Overview
OCR is an acronym for Optical Character Recognition. The OCR engine software attempts to read each and every letter/number/word on an image, and write it out to various file formats. The results of OCR depend on multiple aspects of the image quality. Paper quality, print type, font style, and print quality of the original document can affect image quality and thus the results of OCR. One of the most widely used file formats on the market today is Adobe PDFs.
The OCR Module has the ability to rapidly convert and output scanned images as PDF files, with the OCR as hidden text in each PDF. The results of the full text OCR module can be editable or non-editable files in a file format and directory of the user’s choice. The OCR result files are stored in the batch folder for future reference.
OCR Panes
The following panes are available as part of the OCR workspace:
Batch Progress
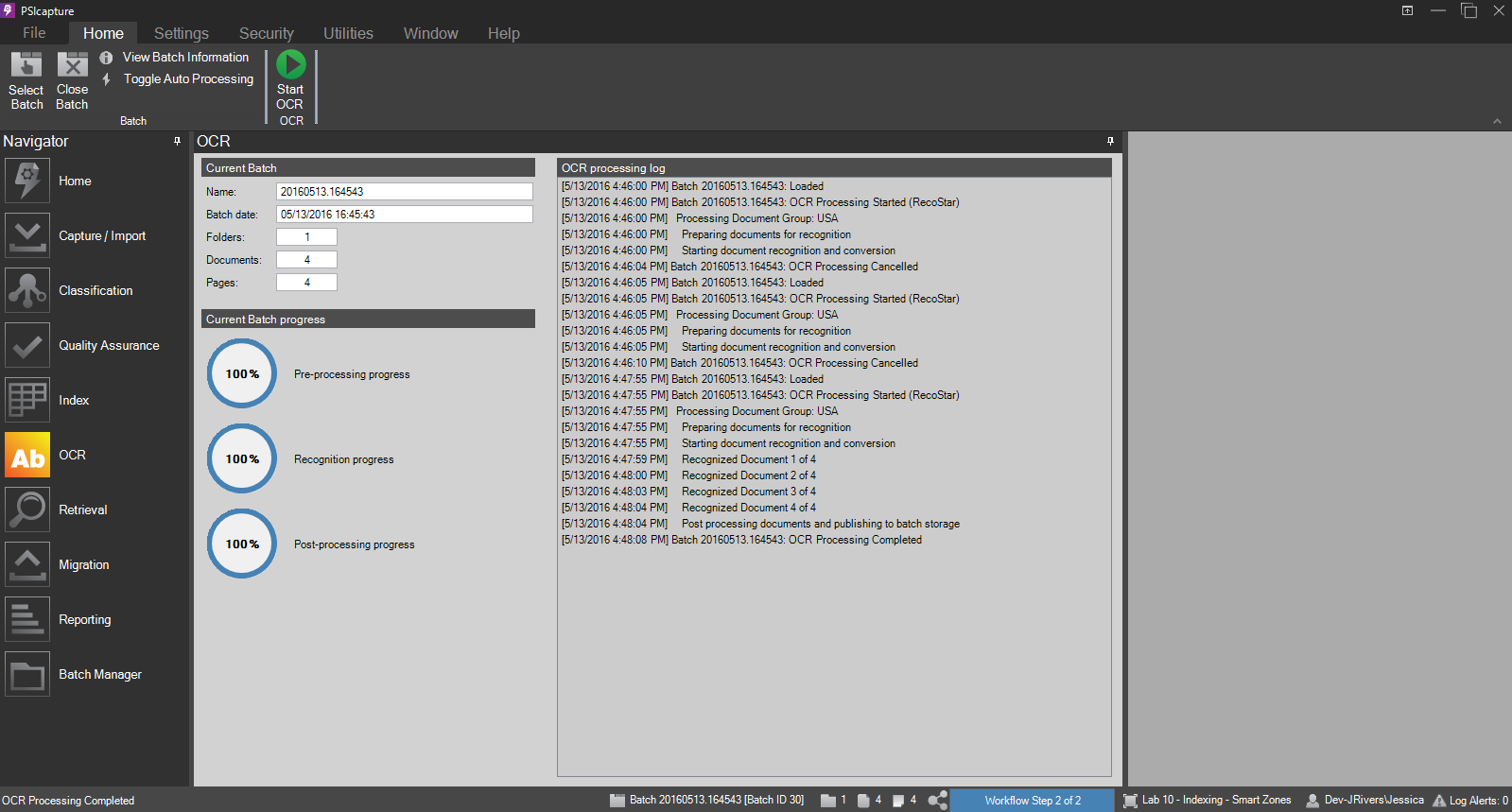
Current Batch - Displays the name and date of the current batch, as well as the folder/document/page count.
Current Batch Progress - Gives graphical representation of the OCR progress.
OCR Log
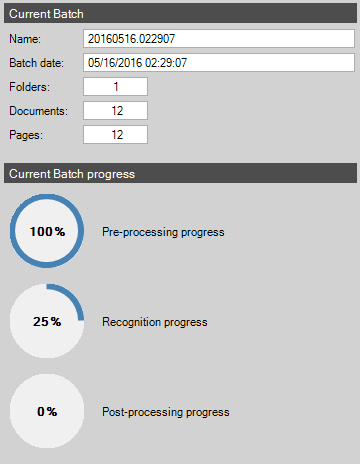
A timestamp of when each batch and document is loaded, processed, and completed.
OCR Home Menu
 |
Choosing this enables the user to select what batch to process in the OCR module. It is useful when returning to the module after suspending a batch. | |
 |
Brings up the Close Batch dialog box. Prompts the user to select one of three options described below:
NOTE: The behavior of the Close Batch dialog box is affected by the settings defined in the "Default action for the "Close Batch" Dialog" section of the capture profile workflow configuration. For more information, see: Capture Profile: Workflow. |
|
 |
Choosing this enables the user to see the current batch information (i.e., batch overrides, batch history, log lookups, etc). | |
 |
Choosing this enables or disables auto processing of the current batch. Any auto processing configurations you made in regards to OCR while configuring the Capture Profile will be applied. | |
 |
Start OCR processing on the batch. |
OCR File Menu
Include Suspended Batches when Auto Processing
Choose whether batches suspended in the OCR workflow step can be automatically processed.
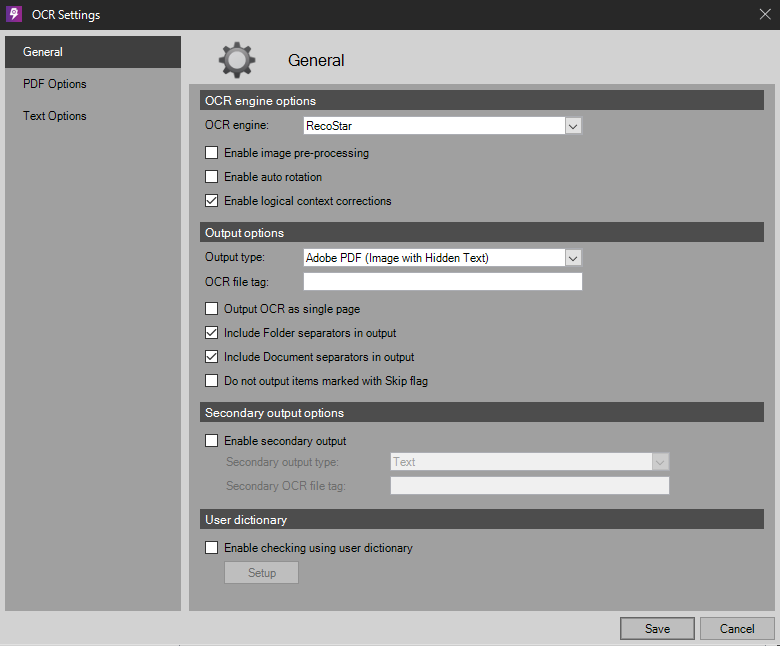
OCR Setup
Brings up the OCR Workflow Step Configuration window:
Comments
Please sign in to leave a comment.