Overview
Standard business forms such as invoices, reports, and purchase orders usually contain tabular data – rows and columns of information that may or may not include things like order codes, prices, and quantities. When using the Classification Module in Capture Profile configuration in order to allow PSIcapture to automatically determine what kind of form it is currently handling, it is also possible to automatically detect the presence of these tables, extract data from them, and potentially use this data to further classify the form. This powerful feature is called Line Item Processing, and is primarily configured in the Classification workflow step.
 |
| Above: A Purchase Order form with a table. |
|---|
Abilities
- Automatically find tables given their header names, and read data from the tables into index fields
- Sample OAI text and raw OCR text to determine if data is safe to read
- Automatic generation of regular expressions based on detected text, paired with the ability to adjust these expressions as necessary
- Fail classification of a form if the table extraction does not produce records
- Feed this data elsewhere for Advanced Data Extraction (ADE) after proper filtering through regular expressions
Limitations
- Scans must be clean – 200 dpi or better, properly oriented, and with minimal grayscale
- Changes in row/column orientation or font face within the table may produce jumbled text, meaningless data, or false positives
- Handwritten tabular data is not supported
- Extraction from multiple tables per form in a single classification rule is not supported
Configuration
Given that users have a Capture Profile created that is using record types, then users are ready to begin configuring the Classification Module to use Line Item Extraction.
First, from the Workflow step, select Classification, and click the Add button to define a new form. The Classification Form Definition window appears:
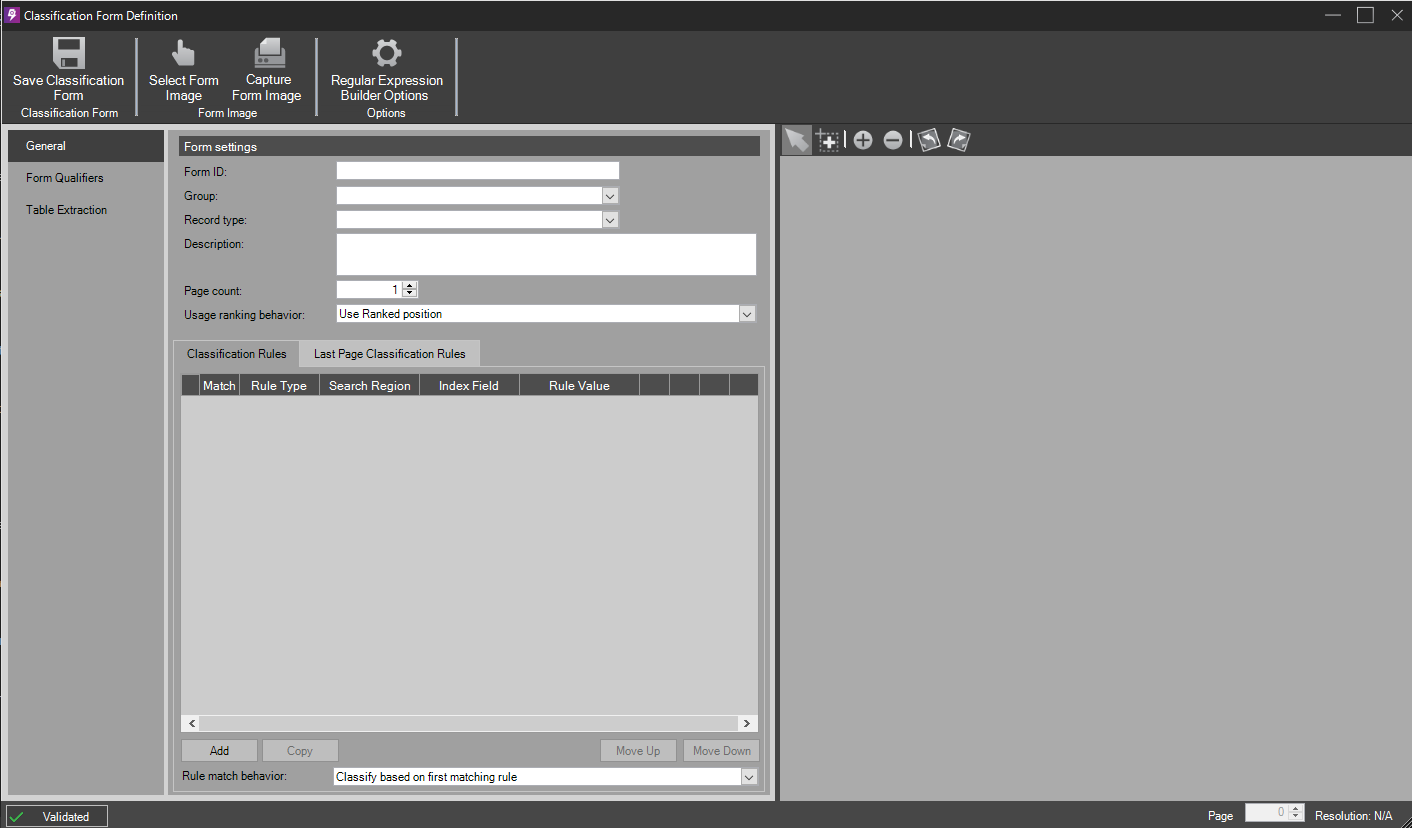
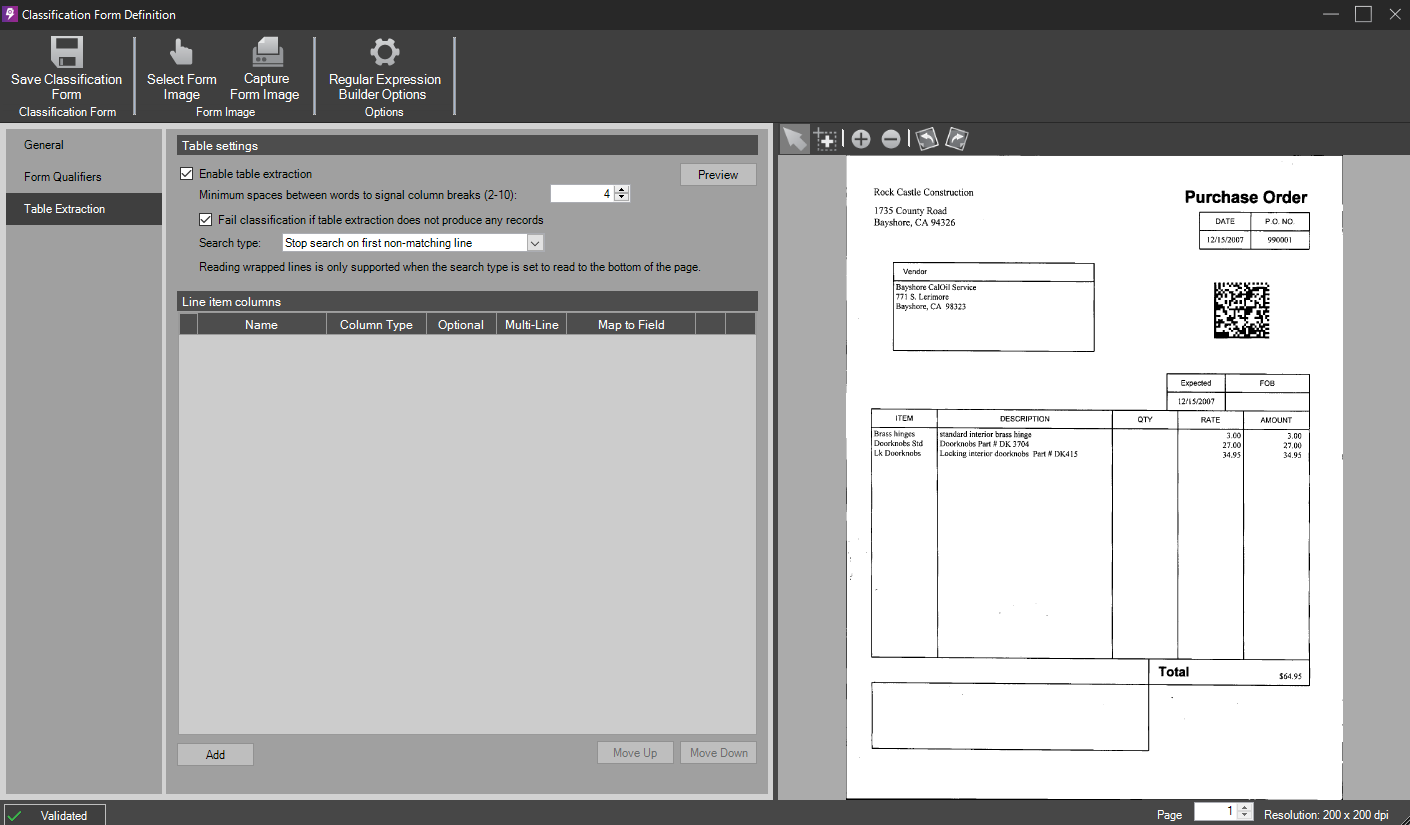
Once all of the desired Form Settings values are entered, add at least one Classification Rule and, optionally, any Form Qualifiers or Last Page Classification Rules. Then, click the Table Extraction from the left side menu to begin configuring Line Item Processing:

In the Table panel, choose Enable Table Extraction to activate the controls within this tab. Users are now ready to configure Line Item Processing.
Options
- Enable Table Extraction: This must be checked in order for Line Item Processing to be active.
- Minimum spaces between words to signal column breaks (2-10) - Allows the user to set the minimum space between columns.
- Fail Classification if table extraction does not produce any records: This will disqualify the scanned page as a member of the current form definition if the tabular data extraction either fails, or succeeds without generating a record.
- Search Type: Line Item Processing can either Stop search on first non-matching line or Search to bottom of page. The former option can be faster, the latter more thorough, though both have valid applications depending on the circumstances of the data. Be sure to consult our PSIGEN Professional Services Representative if this option is unclear.
- Preview: This button will open the Line Item Preview window to provide an updated view of which line items have been successfully detected. Each table row is highlighted as users click or tab through the data in the interface.
- Controls: The Add, Move Up, and Move Down buttons enable the user to create Line Item Columns or reorder them in the list.
Example
The following is an example case of how to use Line Item Processing to extract data from a table automatically during Classification. A completed Capture Profile and sample forms are included below.
Sample Files

Capture Profile Creation
Let's create a new Capture Profile that uses the Line Item Processing feature to scan a set of forms:
- Extract the attached files to a folder on the computer, and open PSIcapture. Additionally, open Page 1 of the forms in an image viewer for reference.
-
Create a new Capture Profile, and provide it a Name and Storage Location.
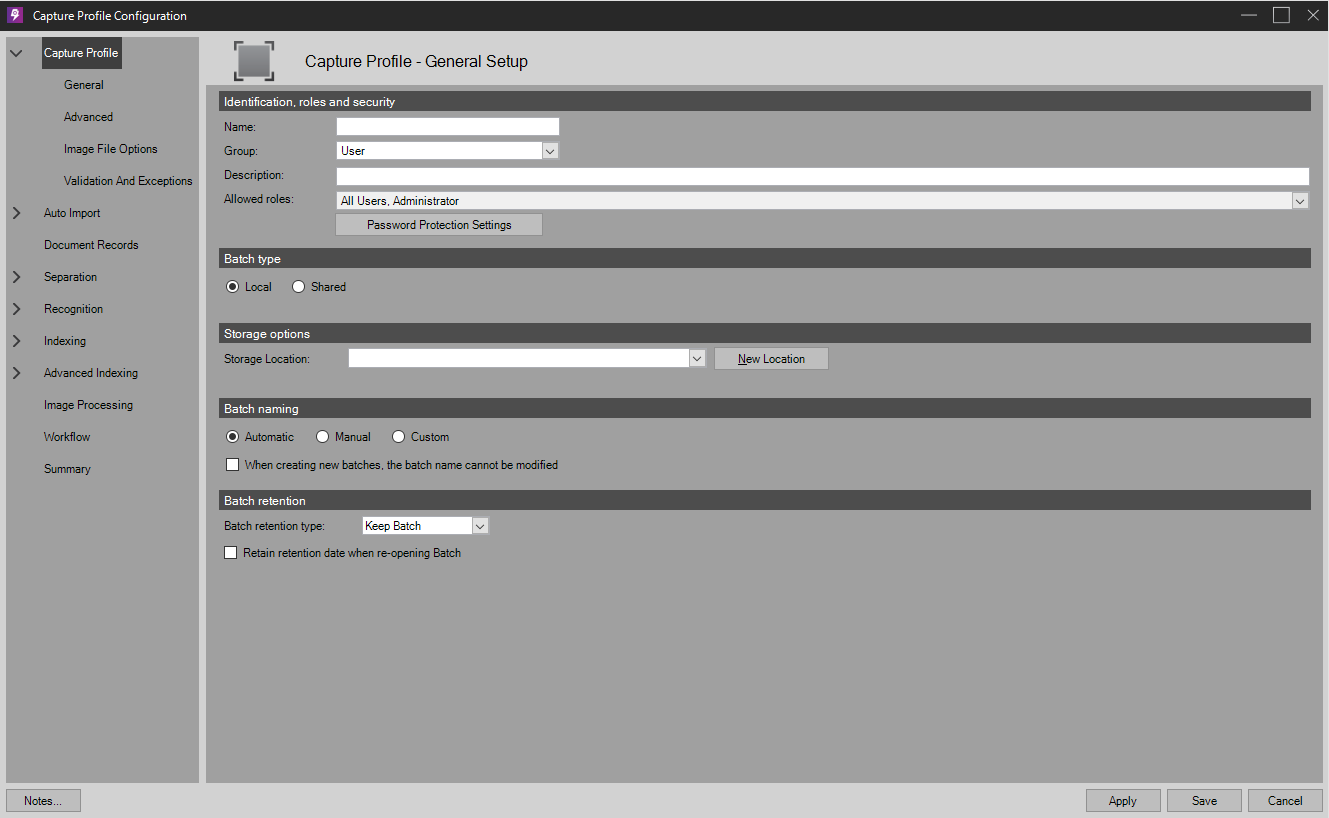
Creating a new Capture Profile -
In the Document Records step, enable the Support Document Record Types feature and configure a sample record type. NOTE: The yellow highlighted record is the default.
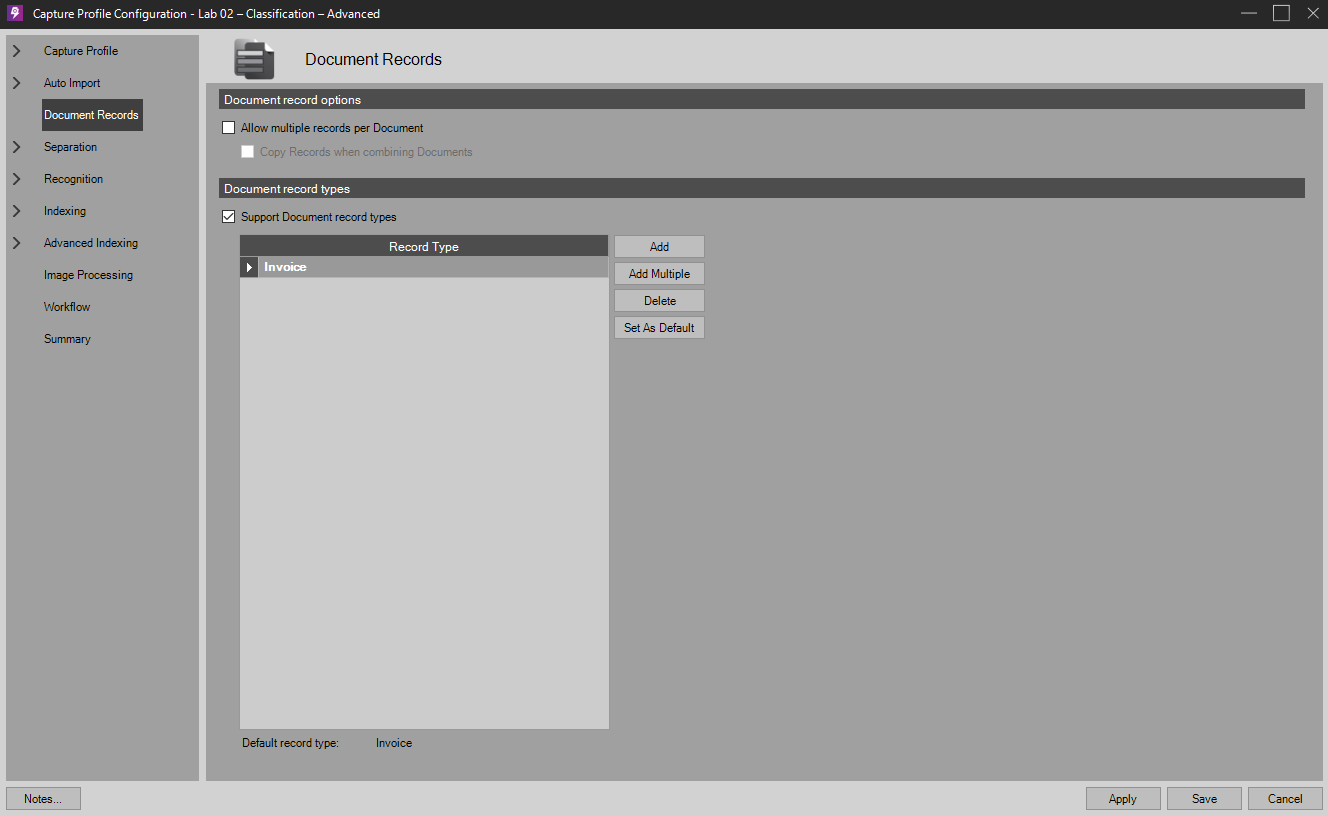
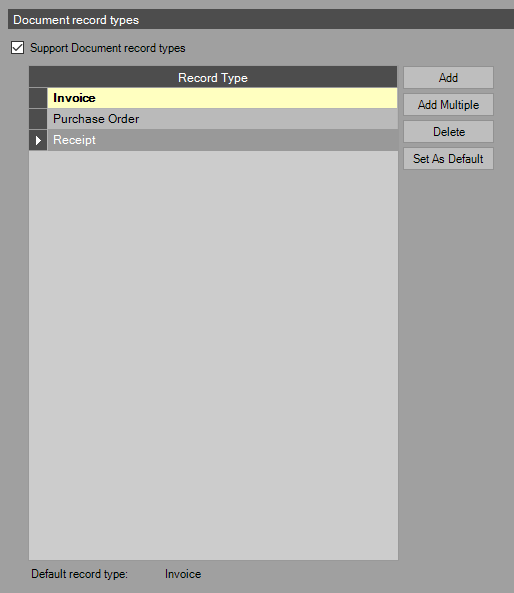
Enabling Record Types and adding a new Record Type -
At the Separation Options step, add a new Separation Document Profile to Separate on new file (Import Only) as shown.
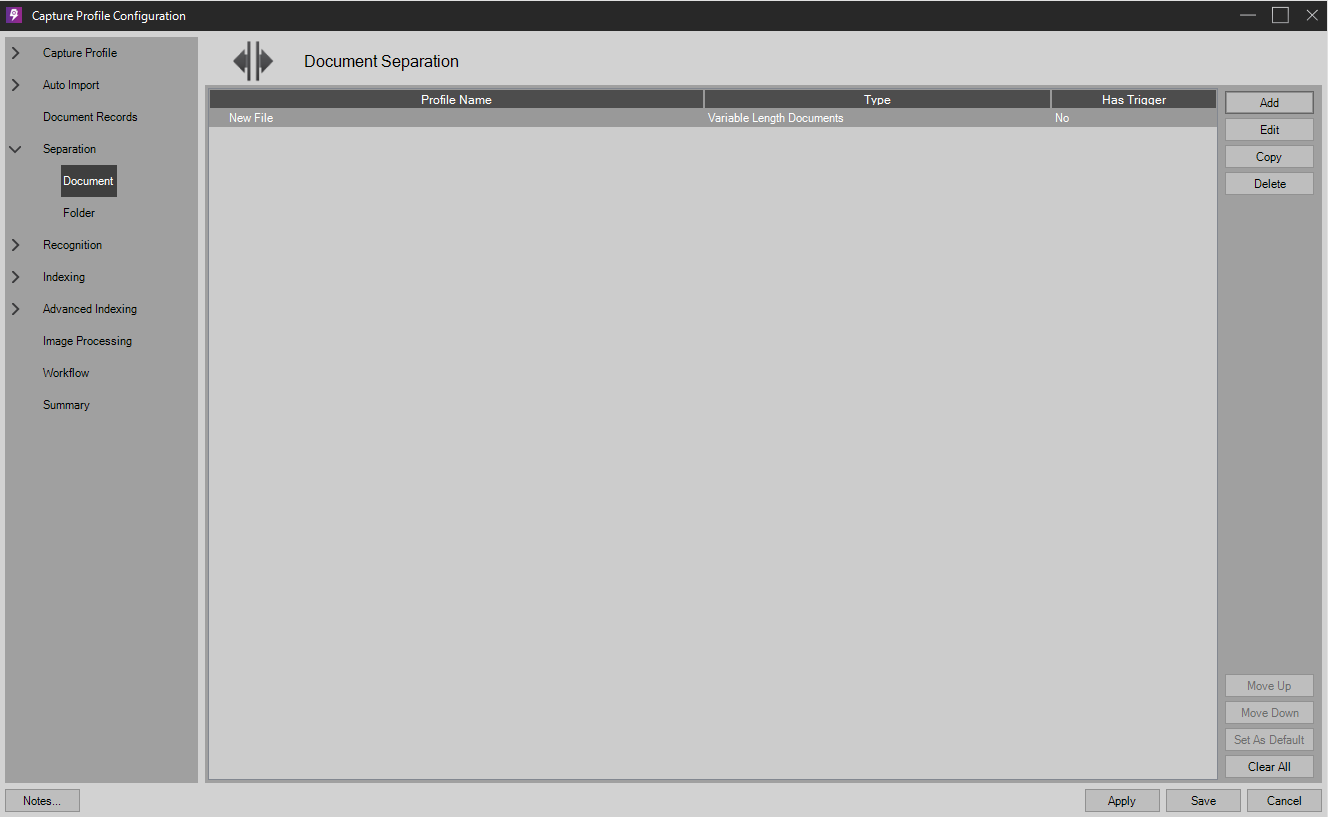
Separating per file imported -
At the Index Data Fields step, create five index fields as shown. These will be the fields that Line Item Processing will map to later on.
Note: In the Quantity field, set the "Default Value" to 1 so that no items ever end up with a quantity of zero in the QA report.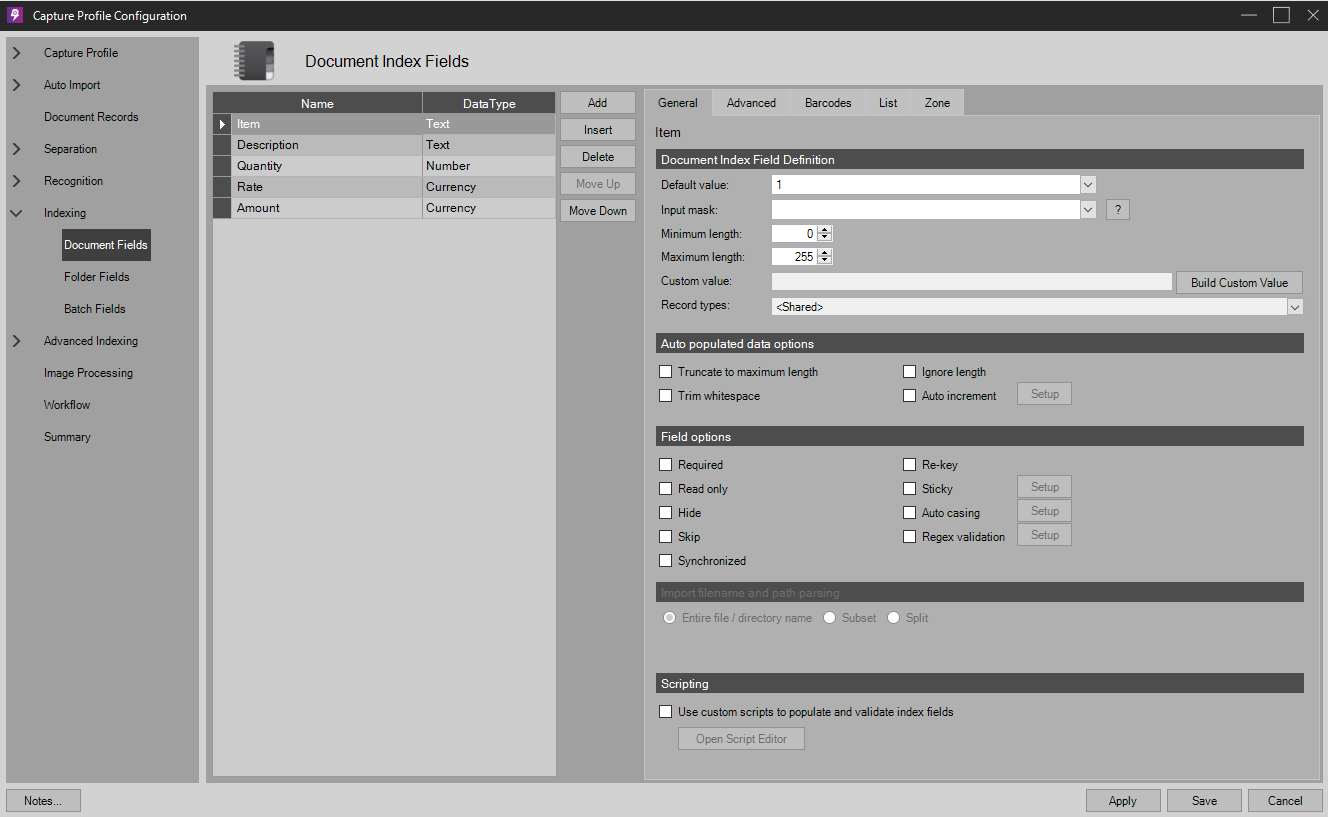
Index Field creation - At the Workflow step, add a Classification Module to begin configuring it.
- Click the Add button to create a new Form Definition; the Classification Form Definition window appears. From here, load the Page 1 file from the sample set.
-
Make at least one Classification Rule by clicking the Add button. The sample Capture Profile qualifies this form based on the OCR Text "Purchase Order" and "P.O. NO."
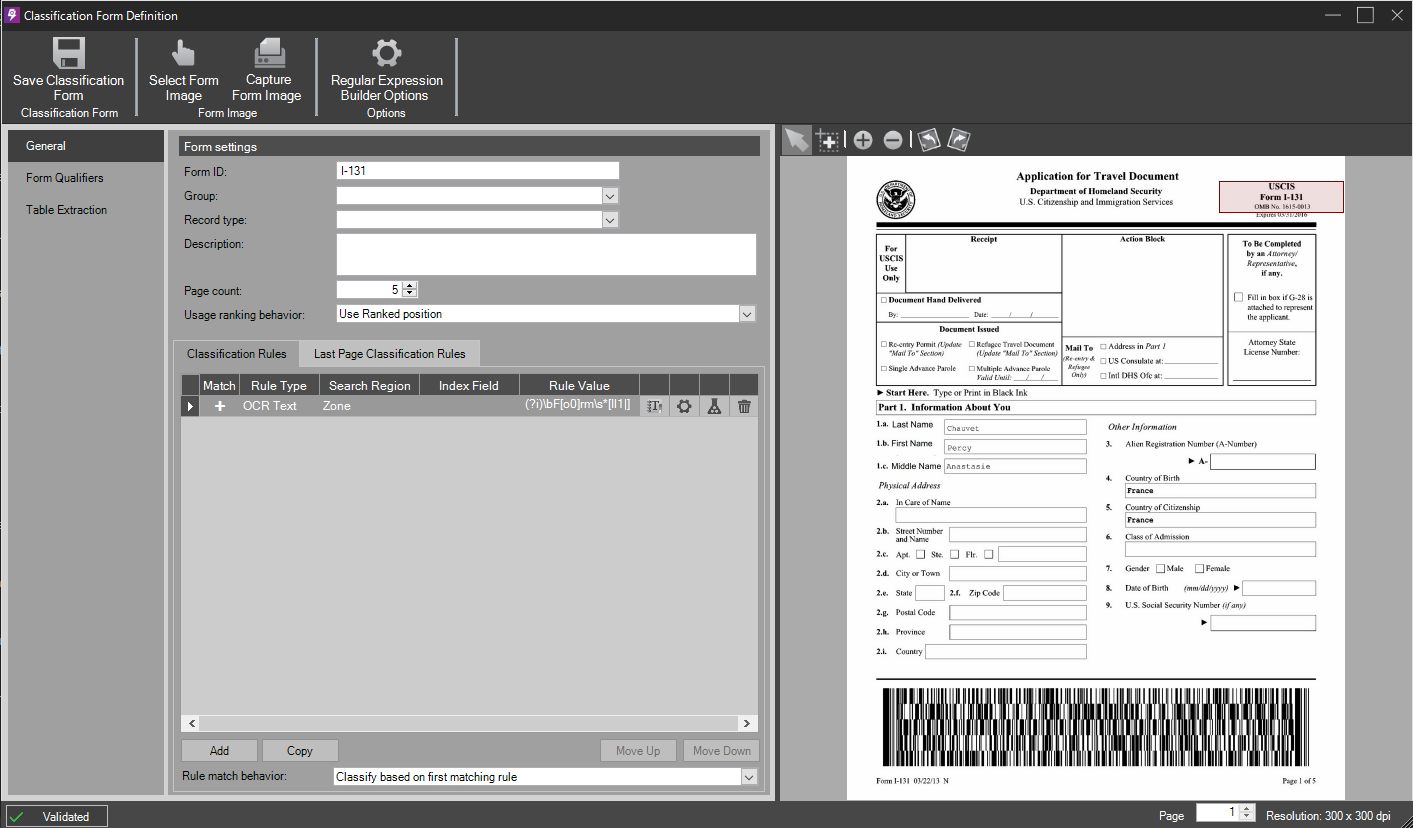
A new Classification rule based on the OCR Text -
Click the Table Extraction - Line Items tab, and check the Enable Table Extraction option to begin configuring Line Item Processing.
Selecting the Line Items tab
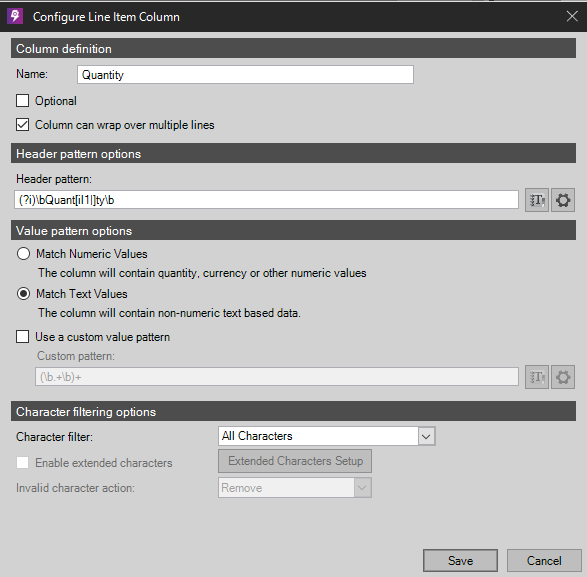
Click the Add button to open the Configure Line Item Column dialog. An OCR Preview window of the form will be displayed. Click the header row called "Item", not the first value in the Item column on the form: The Column Name will be auto populated once you choose the column. Line Item Processing will identify each row for us as long as we construct the table by the header names. NOTE: In versions 6.0.3 and below you will need to click on the OCR butter next to the Header Pattern to point-and-click the column.
Column can wrap over Multiple Lines - When enabled a column can be specified as multi-line in order to specify that the value for extraction should span multiple rows. This setting can be mixed amongst columns such that some are multi-line, and others are not.
Character Filtering allows users to filter each line item column based on the following choices.
Character Filter:
- All Characters
- Alpha Only (a-z, A-Z)
- Numeric (0-9)
- Numeric Extended (0-9, $%#.,)
- Date (0-9, /-)
- Extended Characters Only
- Standard Printable Characters
Enable Extended Characters (the button next to this option allows users to enter addition characters)
Invalid Character Action:
- Do Not Correct
- Remove
- Auto Correct
- Replace with marker (you could correct invalid character's which a * for example)
|
|
| Configuring the first column in our table |
|---|
- The Header Pattern field will now contain a robust regular expression (see above) to identify this text by any means the OCR engine feels is necessary. Click OK to save this column.
-
Repeat the above process for the remaining four columns. For clarity, name each Line Item Column the same as its corresponding table column header, that is, the first one will be named "Item", the second "Description", the third "Quantity", and so on. Once completed, we should have five columns in our table definition, one to match each column within the form.
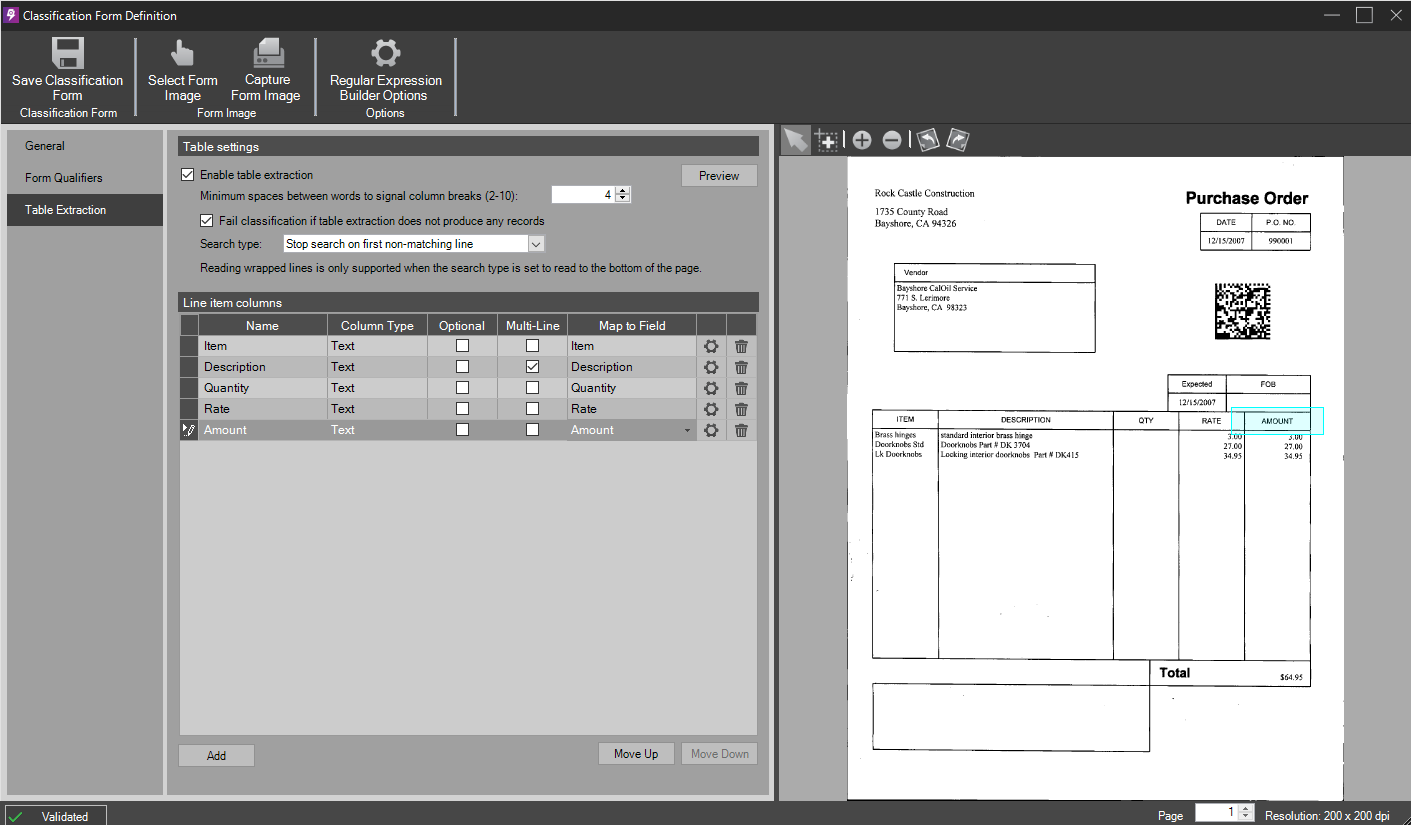
All column definitions added, matching the form -
Click the Preview button to see what the Line Item Processing engine will display. The Preview window appears; note that the lists are blank and no table rows have been detected! Something is not working right. Close the preview window.
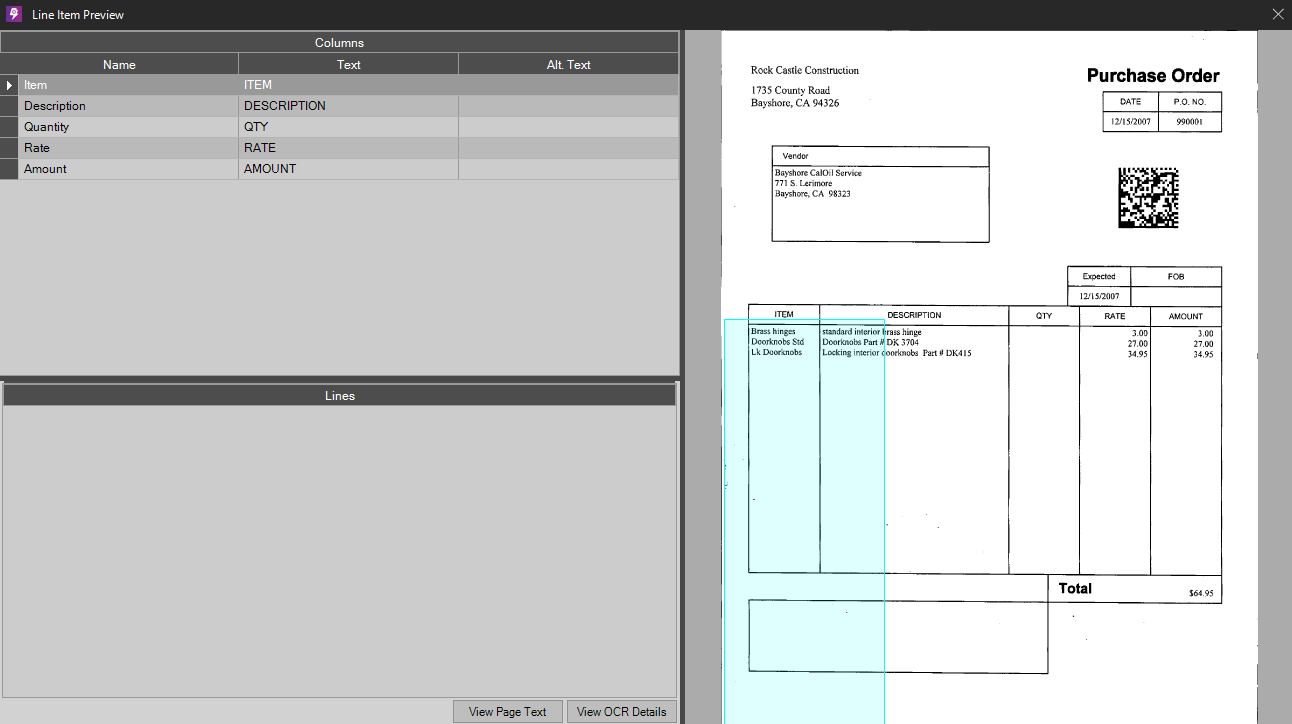
When automatic table detection fails – no values in the lower left panel - In the image viewer, observe each of the sample forms; note the Quantity (or "QTY") column is empty for some or all of the rows. This means that its data set is not necessarily needed to build the table. Looking at some of the other pages, the "Description" column is also sometimes left blank on some of the other pages. Click the configuration button for both the "Quantity" and "Description" columns, and check the box next to Optional. The Line Item Processing engine will no longer halt if a value is not present in this column. Click OK to save.
-
Click the configuration buttons for the "Quantity", "Rate", and "Amount" columns and make sure that the Value Pattern radio button for "Match Numeric Values" is selected. These columns should always be numeric, and though reading them using "Match Text Values" isn't harmful in this scenario, there are situations where this might present a false positive or negative.
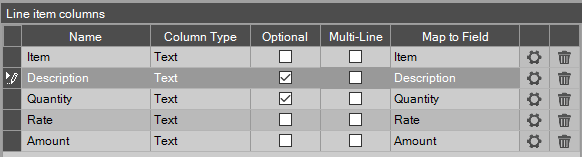
Corrected column types: Description and Quantity are made Optional -
The updated list of columns should appear as shown above. Click the Preview button again; all table rows should be listed. Close the Preview window once you are finished reviewing them.
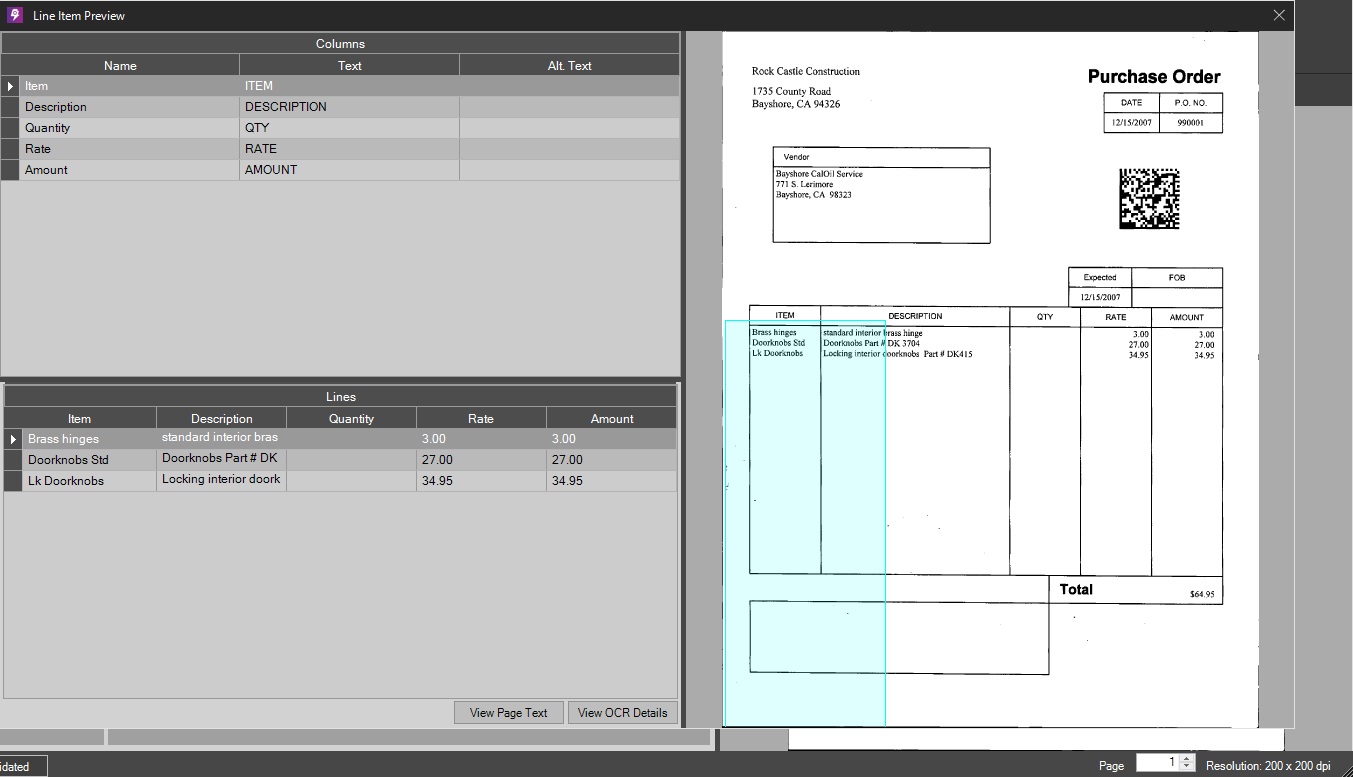
Success – all tablular data extracted into PSIcapture - Click the Save Classification Form button from the toolbar, or press CTRL + S to save this Classification Form Definition. Click Save to exit Classification setup.
-
Add an Index and Quality Assurance module to the workflow as shown, so that PSIcapture can process the results and display them in a QA report. Note that the Index step is still required to process data captured by Line Item Processing because that data is raw and unformatted – again, it is not harmful to ignore this in our scenario, but it is always safe to sanitize data using the Index module in production environments.
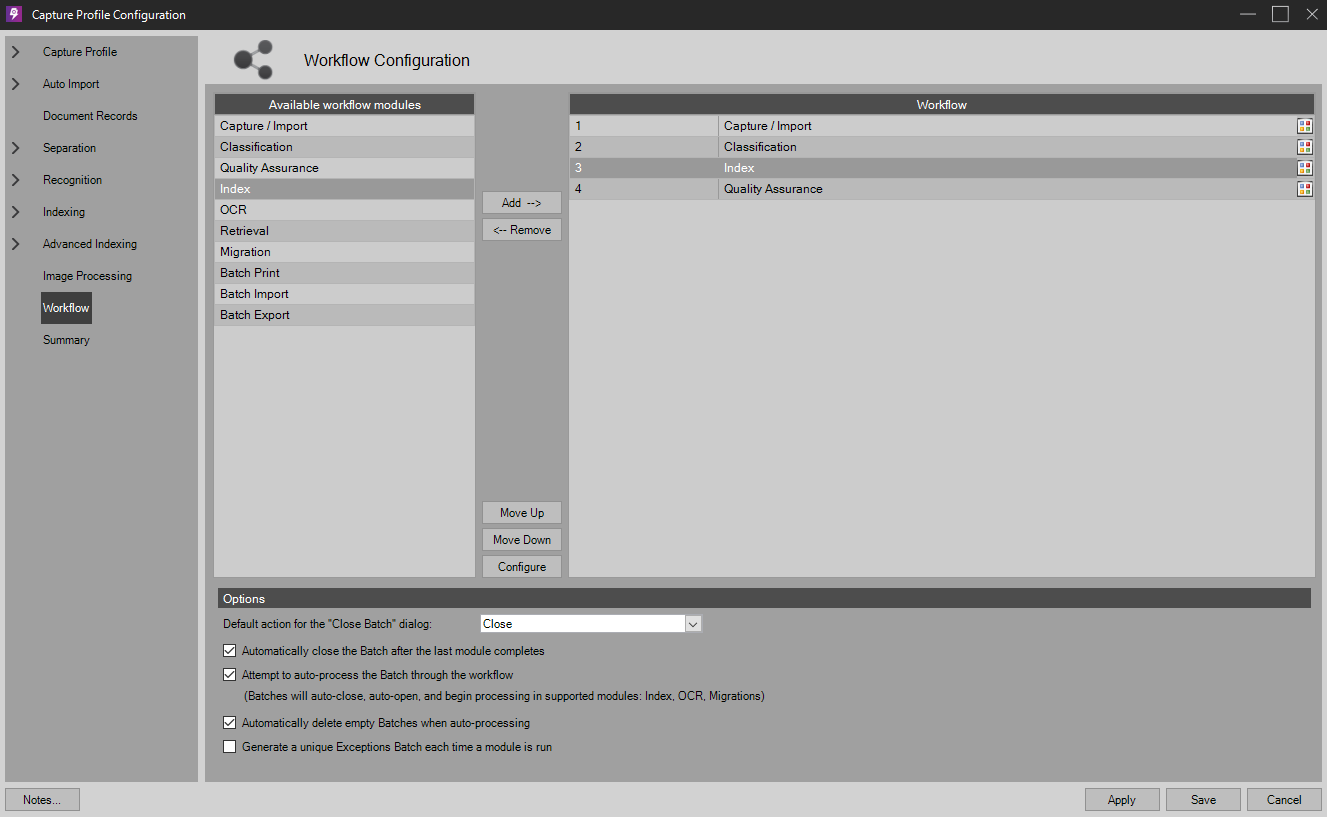
- Click Save to save the Capture Profile, and then use it to process a batch using one or more of the enclosed PO samples.
-
Advance through the Capture Profile – all of the table rows from all of the imported pages should be displayed at the QA step.
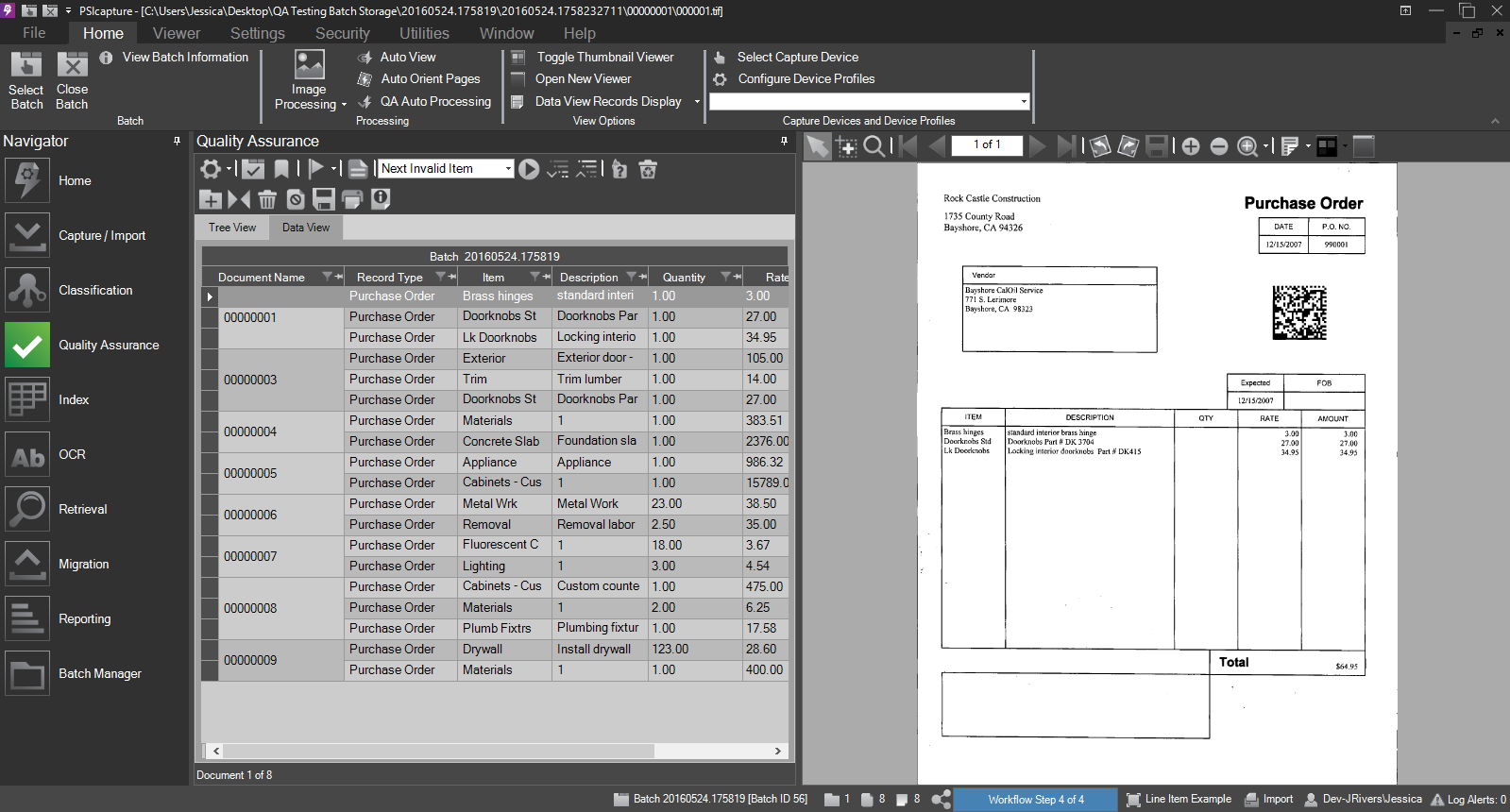
The final QA step of a processed batch, with all records and values displayed
Conclusion
Line Item Processing is a powerful tool that is only lightly touched on in the above scenario – advanced scenarios are possible, involving multiple classifications and complex tables, allowing a Classification scan through even the most complex form sets.
For more information contact a PSIGEN Professional Service representative.
Comments
Please sign in to leave a comment.