| version 7.9.x | Download Pending |
Audience
This article is intended for PSIcapture Administrators.
Overview
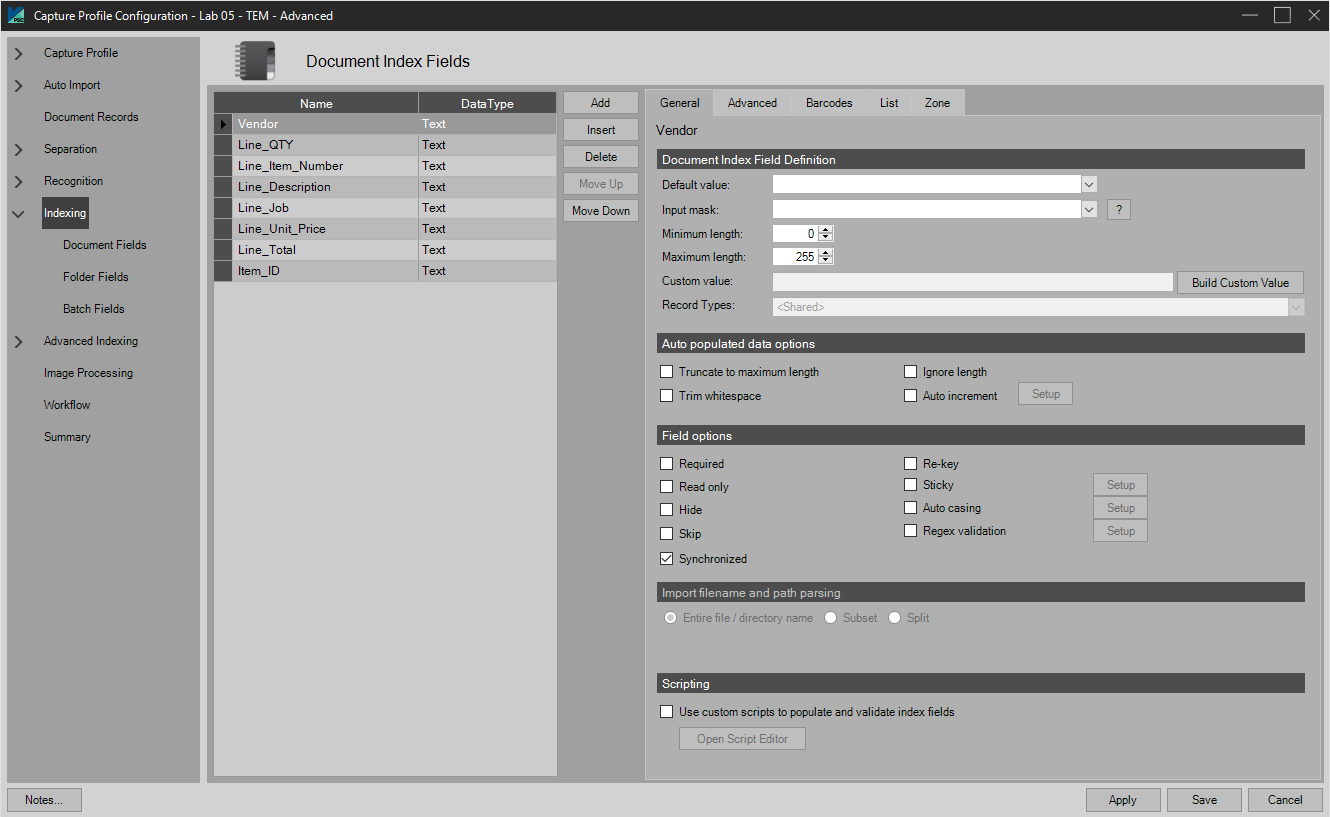
The PSIcapture Capture Profile Configuration: Indexing section is the heart of the configuration area for the index fields that are populated throughout your PSIcapture workflow. These fields can be manually keyed, automatically filled with Smart Zone OCR/ICR, retrieve information from databases via Lookups, and many more deeply customizable options found throughout this section. To begin, we'll briefly differentiate between the three types of index fields you can use in a PSIcapture workflow:
Document Index Fields
These index fields are used to enter data that can be used later to perform queries and document retrieval systems and may be populated by information extracted from the Folder or Batch index fields as well as the methods described below.
Folder Index Fields
These index fields are useful for creating and managing folder based capture applications, such as patient medical records and mortgage files, wherein each folder contains multiple types of documents that need to be organized and tracked at the folder level. The tabs within this section are the same as Document Index Fields but there are a few noted differences in the available options.
Batch Index Fields
These index fields can be defined to contain information about all the documents in the batch such as the date, user who creates the batch, box number etc. The tabs in this section are the General and Selection List tabs only and function as described below.
If the field is a Batch Index Field, the user can also perform a sum of the Document Index Field and populate this Batch Index Field with that sum automatically. This option is only available if users select a numeric Data Type and can only add Document Index Fields that have the same Data Type as the Batch Index Field. For example, if the user has a document index field called ‘PO Amount’ and they want to have a Batch total of all the purchase orders in said batch, a Batch Index Field called ‘Batch Total’ can be created. The user would then select ‘Sum.PO Amount’ for the default value of the ‘Batch Total’ field. If the field is a Document Index Field, the user can populate the Batch Index Field automatically using the contained values.
Index Field Setup
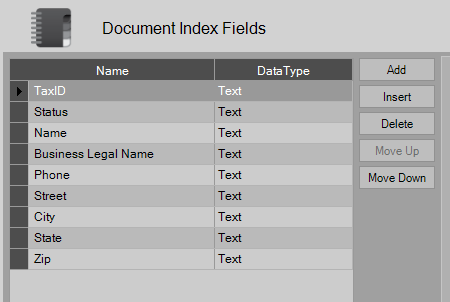
Add
Index Fields may be added by pressing the ‘New’ button then entering the name of the index field and its data type in the Index Fields table.
Name
The name of the field can be anything the user chooses, but it should be descriptive so that data entry users can easily identify what data should be entered in that field. Also if the user plans to populate the field automatically using database lookup, it may be useful though not required, to name the field with the same name as the matching field name for each field in the database used to perform the lookup.
Data Type
The following Data Types are available for index fields:
- Text – any character
- Number – numbers with decimal places
- Currency – numbers with 2 decimal places
- Whole Number – numbers with no decimal places
- Decimal– numbers only with decimal places
- Date/Time – date and time (use default values to specify date only)
- Yes/No – Boolean yes or no
- Memo – large text field
Insert
Creates a new Index Field directly prior to the curently selected Index Field
Delete
Select the row of the field that the user would like to delete and press delete
Move Up
Select the row of the field that the user would like to move up in the order of the fields
Move Down
Select the row of the field that the user would like to move down in the order of the fields
Document Index Fields Breakdown
Document Index Fields: General
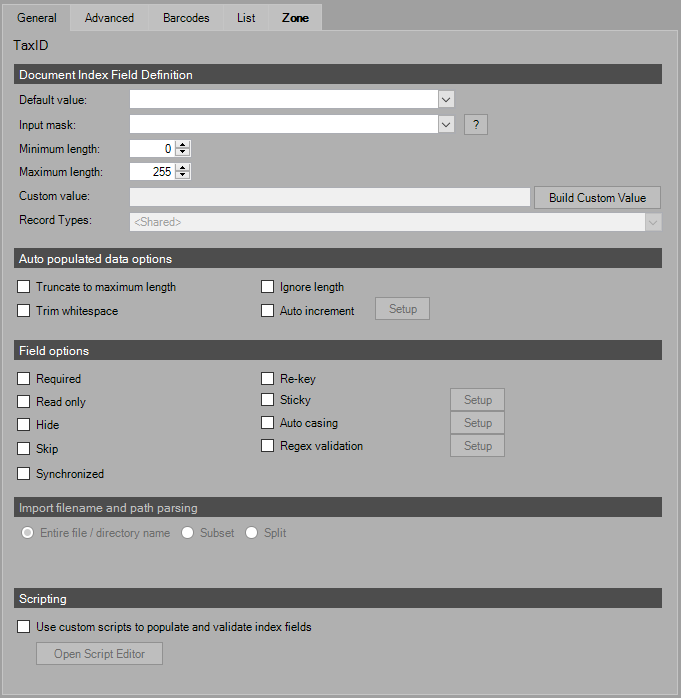
NOTE: The user must select one of the defined fields in order to configure the General, Advanced, Barcodes, List, or Zone tabs for that field. The field highlighted is displayed as shown regardless of which tab the user selects.

Document Index Field Definition
Default Value
This option allows the user to specify a default value in which to populate this field. This can either be a predefined default value, chosen from the system defined list or a manually entered value.
The following system defined default values can also be selected:
NOTE: Depending on the Data Type of the field chosen items in this list may or may not be present
- Today’s Date – mmddyyyy (as defined in the local windows system)
- Today’s Date/Time – mmddyyy.hhmmss (as defined in the local windows system)
- Capture Profile Name – the name of this Capture Profile
- User Name – the logged in domain user name (Example: PSIGEN\scanner1)
- User Name (No Domain)–the logged in user name only (Example: scanner1)
- User Display Name - Display name for the user's profile (Example: Scanning User)
- Capture Station – the name of the station used to capture the batch
- Batch Name – the batch name
- Folder Separator Value – the value used to separate the Folder (usually a barcode value) Folder Index fields only
- Document Separator Value – the value used to separate the document (usually a barcode value)
- Folder Name – the value of the name of the folder
- Folder Number – the number of the folder relative to the batch it is contained in
- Document Number – the number of the document number relative to the batch it is contained in
- Document Page Count – the number of pages in the document
- Import Filename – the windows filename including its extension
- Import Filename(no extension) – the windows filename without its extension
- Import File Path – shows the file path if the import source is from a local or a mapped drive
- Import File UNC Path – shows the file path if the import source is from a network location
- Import File Directory Path – shows the file directory path if the import source is from a local or mapped drive
- Import File Directory UNC Path – shows the file directory path if the import source is from a network location
- Import File Create Date – the date which the file is created
- Import File Create Date/Time – the date/time which the file is created
- Import File Modify Date – the date which the file was last modified
- Import File Modify Date/Time – the date/time which the file was last modified
- Import File Page Number - the page of the imported document
- Import Path Elements (1-10) – the path elements of the file (example C:\Images\best buy\sales orders\00001.tif –if during the Import or Auto Import process the users selection was best buy then selecting Import Path Element 2 would place “sales orders” in the index field
- Import Path Parent (1-10)– the parent path elements of the file (example C:\Images\best buy\sales orders\00001.tif – if during the Import or Auto Import process the users root selection was the sales orders directory then selecting Import Parent Path Element 1 would place Images in the index field
- Begin Bates Stamp (1-5) – the position of the begin bates stamp value to put in this index field
- End Bates Stamp (1-5) – the position of the end bates stamp value to put in this index field
- OCR Value – The default OCR value as recognized during the Capture/Import step.
- Begin Imprinted Value – the begin imprinted value of each document
- End Imprinted Value– the last imprinted value of each document
NOTE: Additional options will appear after defining Batch or Folder Index Fields. They will appear as [Batch Field.(the name of the field)] or [Folder Field.(the name of the field)] which allows the user to automatically populate the Document Index Field with those Batch or Folder Field values.
Input Mask
There many options that may be selected that will limit what the user can enter into the field when manually indexing. This feature provides a visual mask and forces the user manually indexing to adhere to the defined format. Choose from a number of commonly used masks via the dropdown list, or write custom masks with Regular Expressions.
NOTE: This feature in NOT used in validation and is not used for validation when auto populating a field; it may be required to display the return values in an index field.
| Character | Description | |
|---|---|---|
| # | Digit placeholder - Character must be numeric (0-9) and entry is required. | |
| . | Decimal placeholder - The actual character used is the one specified as the decimal placeholder by the system's international settings. This character is treated as a literal for masking purposes. | |
| , | Thousands separator - The actual character used is the one specified as the thousands separator by the system's international settings. This character is treated as a literal for masking purposes. | |
| : | Time separator - The actual character used is the one specified as the time separator by the system's international settings. This character is treated as a literal for masking purposes. | |
| / | Date separator - The actual character used is the one specified as the date separator by the system's international settings. This character is treated as a literal for masking purposes. | |
| \ | Treat the next character in the mask string as a literal. This allows users to include the '#', '&', 'A', and '?' as well as other characters with special meanings in the mask. This character is treated as a literal for masking purposes. | |
| & | Character placeholder - Valid values for this placeholder are ANSI characters in the following ranges: 32-126 and 128-255 (keyboard and foreign symbol characters). | |
| > | Convert all the characters that follow to uppercase. | |
| < | Convert all the characters that follow to lowercase. | |
| A | Alphanumeric character placeholder - For example: a-z, A-Z, or 0-9. Character entry is required. | |
| a | Alphanumeric character placeholder - For example: a-z, A-Z, or 0-9. Character entry is not required. | |
| 9 | Digit placeholder - Character must be numeric (0-9) but entry is not required. | |
| - | Minus sign when followed by a number section defined by series of 'n's (like in "-nn,nnn.nn") indicates that negative numbers are allowed. When not followed by a series of 'n's, it's taken as a literal. Minus sign will only be shown when the number is actually negative. | |
| + | Plus sign when followed by a number section defined by series of 'n's (like in "-nn,nnn.nn") indicates that negative numbers are allowed. However, it differs from '-' in the respect that it will always show a '+' or a '-' sign depending on whether the number is positive or negative. | |
| C | Character or space placeholder - Character entry is not required. This operates exactly like the '&' placeholder, and ensures compatibility with Microsoft Access. | |
| ? | Letter placeholder - For example: a-z or A-Z. Character entry is not required. | |
| n | Digit placeholder - A group of n's can be used to create a numeric section where numbers are entered from right to left. Character must be numeric (0-9) but entry is not required. | |
| mm, dd, yy | Combination of these three special tokens can be used to define a date mask. mm for month, dd for day, yy for two digit year and yyyy for four digit year. Examples: mm/dd/yyyy, yyyy/mm/dd, mm/yy. | |
| hh, mm, ss, tt | Combination of these three special tokens can be used to define a time mask. hh for hour, mm for minute, ss for second, and tt for AP/PM. Examples: hh:mm, hh:mmtt, hh:mm:ss. | |
| {date} | {date} token is a place holder for short date input. The date mask is derived using the underlying culture settings. | |
| {time} | {time} token is a place holder for short time input. Short time typically does not include the seconds portion. The time mask is derived using the underlying culture settings. | |
| {longtime} | {longtime} token is a place holder for long time input. Long time typically includes the seconds portion. The long time mask is derived using the underlying culture settings. | |
| {double:i.f:c} | {double:i.f:c} is a place holder for a mask that allows floating point input where i and f in i.f specify the number of digits in the integer and fraction portions respectively. The :c portion of the mask is optional and it specifies that the inputting of the value should be done continuous across fraction and integer portions. For example, with :c in the mask, in order to enter 12.34 the user types in "1234". Notice that the decimal separator character is missing. This alleviates the user from having to type in the decimal separator. | |
| {double:-i.f:c} | Same as {double:i.f:c} except this allows negative numbers. | |
| {currency:i.f:c} | Same as {double:i.f:c} except the mask is constructed based on currency formatting information of the underlying format provider or the culture. It typically has the currency symbol and also displays the group characters. | |
| {currency:-i.f:c} | Same as {currency:i.f:c} except this allows negative numbers. | |
| Literal | All other symbols are displayed as literals; that is, they appear as themselves. |
Users can also escape the mask with {LOC} character sequence to indicate that symbols in the following table should be mapped to the associated symbols in the underlying culture settings.
| Character | Definition | |
|---|---|---|
| $ | Currency Symbol | |
| / | Date Separator | |
| : |
Time Separator |
|
| , | Thousands Separator | |
| . | Decimal Separator | |
| + | Positive Sign | |
| - | Negative Sign |
Min. Length
This defines the Minimum length of ‘Text’ ‘Data Type’ fields ONLY. If the length of the populated data is less than the minimum length, validation will fail on that document.
Max. Length
This defines the Maximum length of ‘Text’ ‘Data Type’ fields ONLY. If the length of the populated data is greater than the maximum length, validation will fail on that document.
Custom
User can create a custom index field with the use of Constants and/or a combination of other Fields. Click “Build” to create a Custom Index Field.
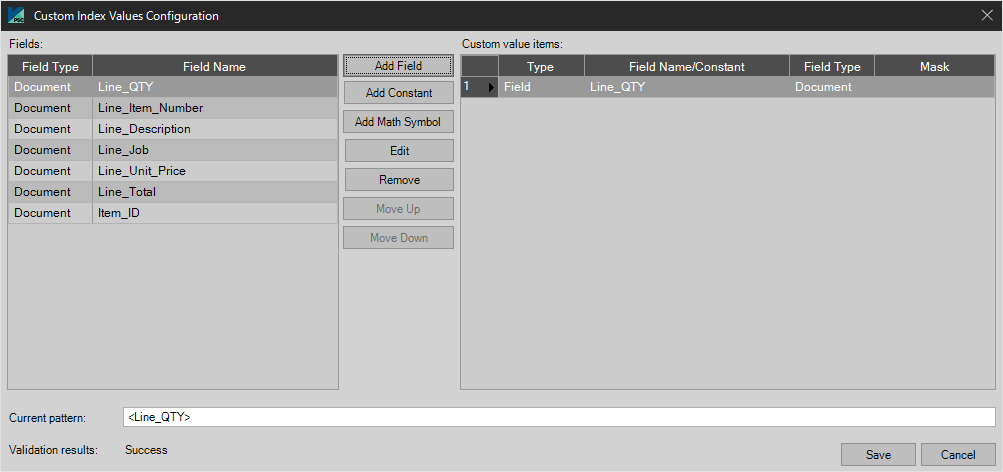
Users can use a combination of the following options to create a custom value:
- Field - Uses a current index field value to populate.
- Constant - Uses custom inputted information.
- Math Symbol - This allows the user to use math symbols to calculate the custom value.
Record Type
In multiple record indexing mode where record types had previously been defined, each index field can be assigned to a specific record type, or be shared among all record types.
NOTE: “Allow Multiple Records Per Document” and “Support Document Record Types” must be enabled and configured in Capture Profile Configuration/General (Part 2) in order to make a selection.
Auto Populated Data Options

Truncate to Max. Length
Select this option for 'Text’ ‘Data Type’ fields that are being populated automatically by methods like barcode, zone OCR, Database Lookup, etc., where it is possible that the data captured may exceed the maximum length permitted for the index field.
Ignore Length
Select this option for 'Text’ ‘Data Type’ fields that are populated automatically by methods like barcode, zone OCR, Database Lookup etc., where the desired result is to have all data regardless of the Max Length value populate the field. Max Length will be ignored during validation if data is auto populated.
Auto Increment
This allows a numeric field to be setup to be an auto-incremented number.
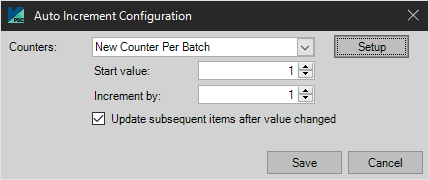
Auto Increment Configuration
Auto Increment Options
Selecting “New Counter Per Batch” will cause the counter to start at the Start Value with each new batch.
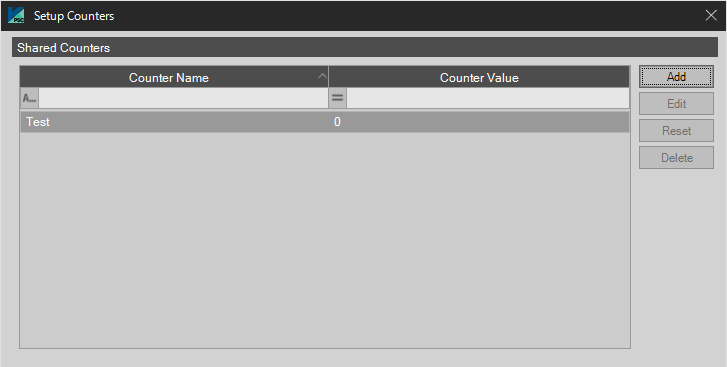
Setup
Selecting Setup will bring up the main Configuration Shared Counters Setup Counters dialog box allowing the user to choose one of the defined counters or create a new one. See the Shared Counters in the System Configuration section of this manual for more information.
Start Value
This is the starting value from which the user wishes to begin incrementing.
Increment By
This is the value by which the user wishes the counter to increment.
Update subsequent items after value changed
Select this option will cause subsequent records after the record being changed to also be changed accordingly (example: record 3 has the value 3 and the user changes it to 5 and the Increment By value is 1 then record 4 will have the value 6).
Trim Whitespace
Deletes whitespace at the end of any values entered in the index field.
Field Options

Required
Whether this field requires data to be entered.
Skip
If selected, this field will be skipped over when the user presses tab or enter during navigation between index fields.
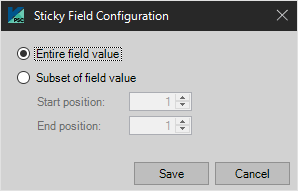
Sticky
If selected the data in this field will remain in this field for each following document until changed. Click “Setup” to choose to populate subsequent fields with the entire value or a subset value. In order to determine the subset, a start and end position must be defined.
Read Only
Whether this field is read only.
Hide
If selected, this field will not be displayed to the user.
Re-Key
This option is used in conjunction with a second index workflow step. Once this option is selected, the field will need to be re-entered. When re-entering a field in Re-index (the second Index step in the workflow), if the re-entered value does not match the previously entered data, the user is warned that the expected value is the first value keyed in the first indexing workflow step. The user is then prompted to either keep the original value or override it with the newly entered value.
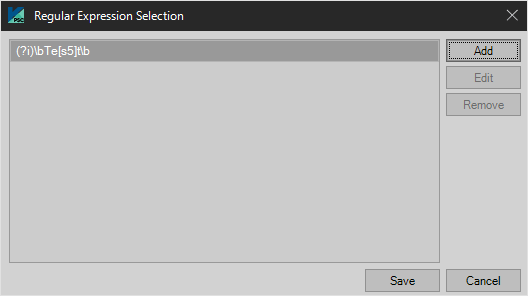
Regex
Further manipulate the data entered in the index field through the use of Regular Expression. Click “Setup” to configure.
This displays expressions currently in use. Click “Add” to add more.
For more information on Regular Expressions please see Advanced Data Extraction section. PSIcapture utilizes the .Net standard for Regular Expressions.
User can write custom expressions or click “Select From Global List” to display Regular Expressions Manager and chose pre-existing expressions.
Synchronized
Synchronized is used for multi-record processing and causes the selected index field to remain constant between all records on that document. Any changes to one record will update this index field on all other records for the active document.
Auto Casing

Auto Casing will adjust the case of all characters to the setting selected.
Use Custom Validation Script
Use scripts to validate each index field after entered. Click “Edit” to bring up the Script Editor.
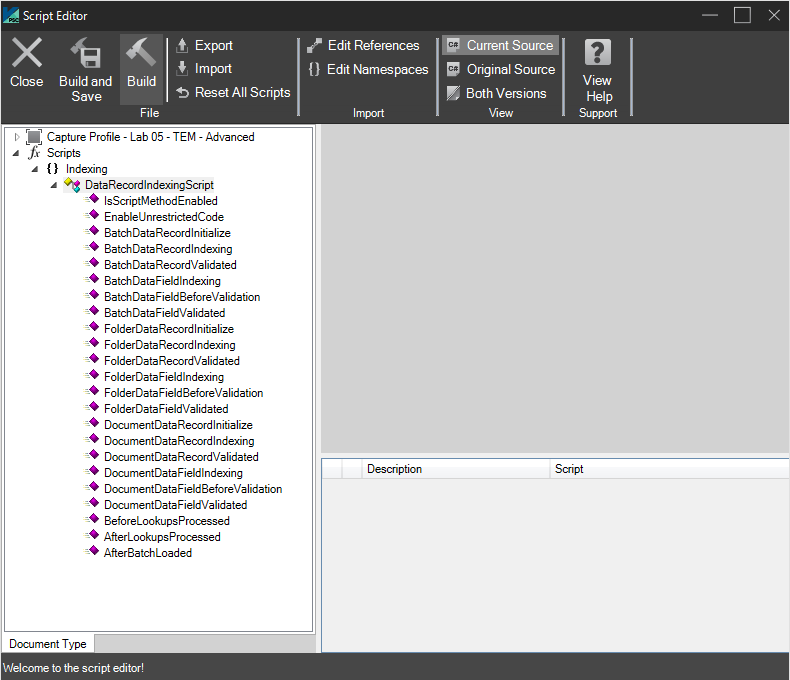
For more information on scripting please see the scripting section of this Administrators Guide.
Document Index Fields: Advanced
Additional options for auto populated data is configured here. Users now have the ability to link specific regular expressions to Record Types. This technology is key in processing different forms, and allows extensive flexibility in data extraction.
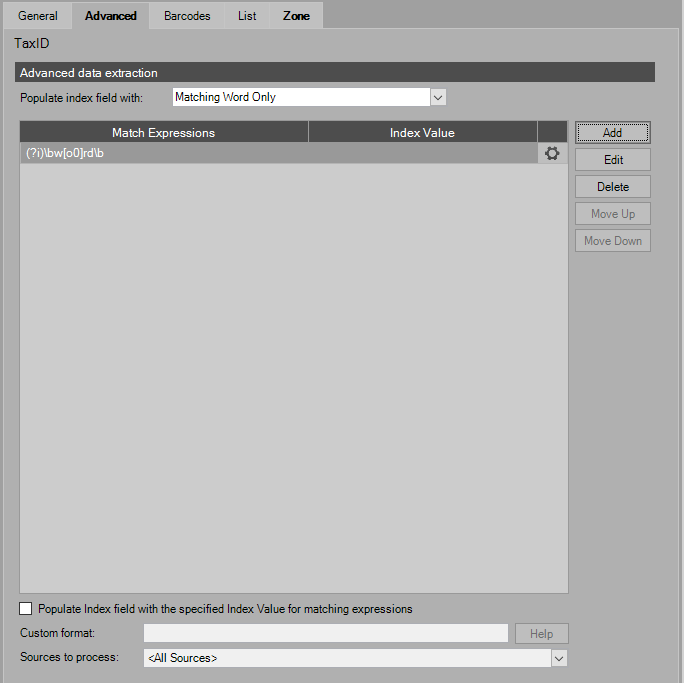
Auto Populated Data Settings
Populate Index Field with
Populate index field with Entire Value, Matching Word Only, and Matching Word Only Custom Format.
Match Expressions
Use regular expressions to extract and format data from captured images to populate image fields. Users have the ability to assign the expression to All Classification Forms, or to pick and choose the Classifications Forms that will use the chosen expression. Users have the ability to filter items by Record Type, Classification Form, or checked/unchecked.
Index Value
The Index Value column displays the value entered to populate an index field as described below in the Regular Expressions section as well as the Populate index field section.
Add/Edit
Brings up Regular Expression Editor to input expression(s). Here users can enter a regex value, type in what to look for and have PSIcapture generate the regex, or select from a default list of common regex values. Additionally, users can include an Index Value to use to populate an index field when the expression is matched.
Delete
Deletes unwanted expressions
Populate index field with the specified Index Value for matching expressions
This enables the user to populate an index field based on the data input in the Regular Expressions editor on the Index Value text field.
If the Regular Expression and/or Index Value was left blank, then the matched word will fill that index field.
If this option is unchecked, the matching word will fill that index field.
NOTE: This option applies to to both "Matching Word Only" and "Matching Word Only (custom expression)" under Source to Process.
Custom Format
Chose between the whole capture, group 1, group 2, etc.
Example Expression - (?<Group1>[0-9]+)

Sources to Process
Use check boxes to select where match expressions are used to extract index data containing matching words.

Import File/Folder Name Parsing for Default Value

Entire File/Folder Name
The entire file or folder name will be placed in the highlighted index field.

Subset
The value to be placed in the index field will be positional based on what is set in the Start Position and the End Position. In this example only the first 4 characters of the file name would be placed there.

Split
The value to be placed in the index field will be determined by a split character. In this example (fred_123456_utah.tif) the “_” is the split character and element 1 is fred.
Document Index Fields: Barcodes
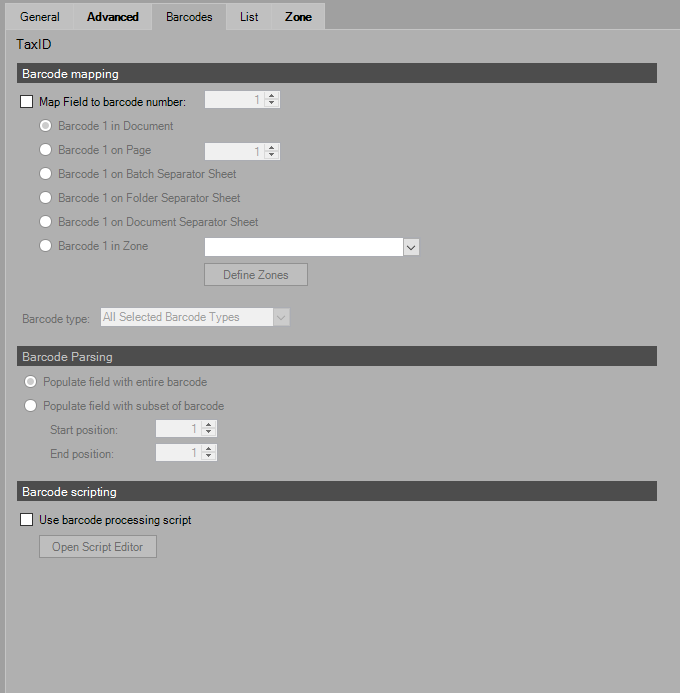
The Barcodes tab specifies whether the selected document index field should be populated using a barcode value. Index fields can be populated by either barcode mapping or with a barcode processing script.
Barcode Mapping
Selecting the Map Field to Barcode Number allows the user to designate which physical or logical (if splitting – see the Capture Profile Configuration /Recognition /Barcode Detection/Barcode Splitting section of this manual) barcode number to the current field. The following options are available for barcode mapping:
Barcode X in Document
Maps to the specified barcode number in the document.
Barcode X on Page X
Maps to the specified barcode number on a particular page of the document.
Barcode X on Folder Separator Sheet
Maps to the specified barcode number on the Folder Separator Sheet.
Barcode X on Document Separator Sheet
Maps to the specified barcode number on the Document Separator Sheet.
Barcode X in Zone Y
Maps to the specified barcode number within a specified zone in the document. This zone can be defined to be anywhere on the document including on a specified page.
Define Zones
Select this to define a new zone.
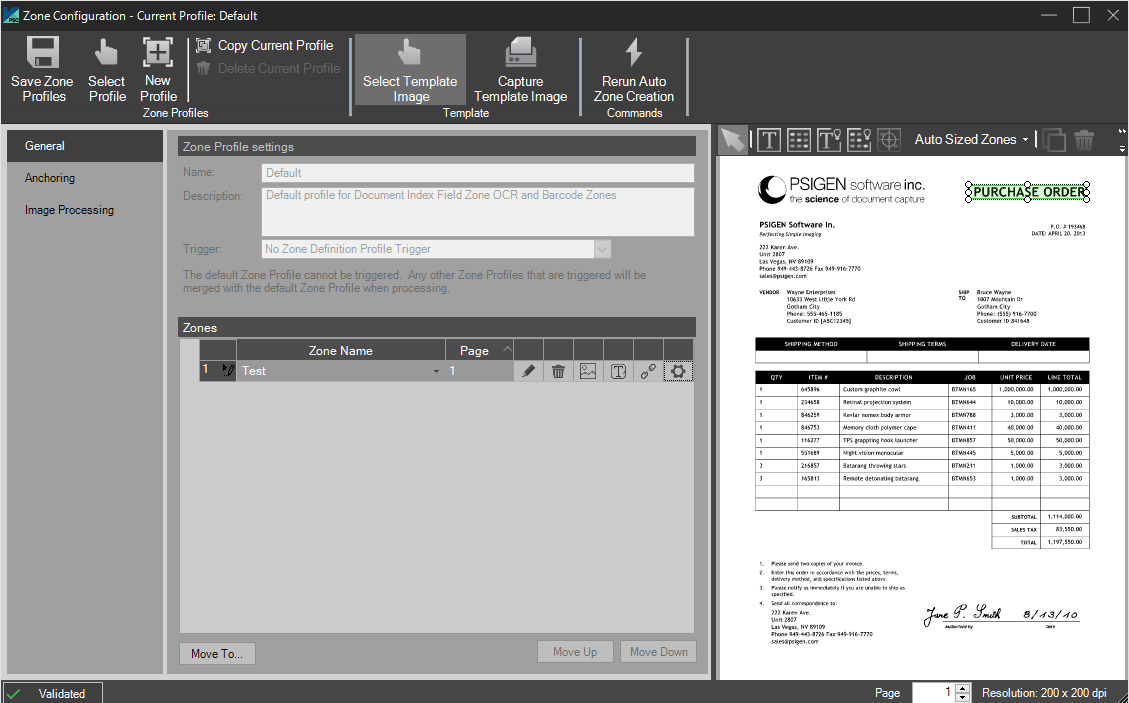
Zone Configuration
The Icons at the top of the above screen allow the user to: Select a template image, save the template with zones, point, manually draw zones, select predefined zones, copy zones, delete zones, group zones, select an area to zoom, zoom in and zoom out.
Anchoring Type
Choose from the Top Left of Page, Barcode, Patch Code, Zone OCR Expression, or Precision OMR Timing Tracks.
Barcode

NOTE: If the user uses a barcode, the type and pattern the user selects must be on the page selected and match.
Barcode Type
Choose a specific type of barcode or all supported barcode types.
Preview
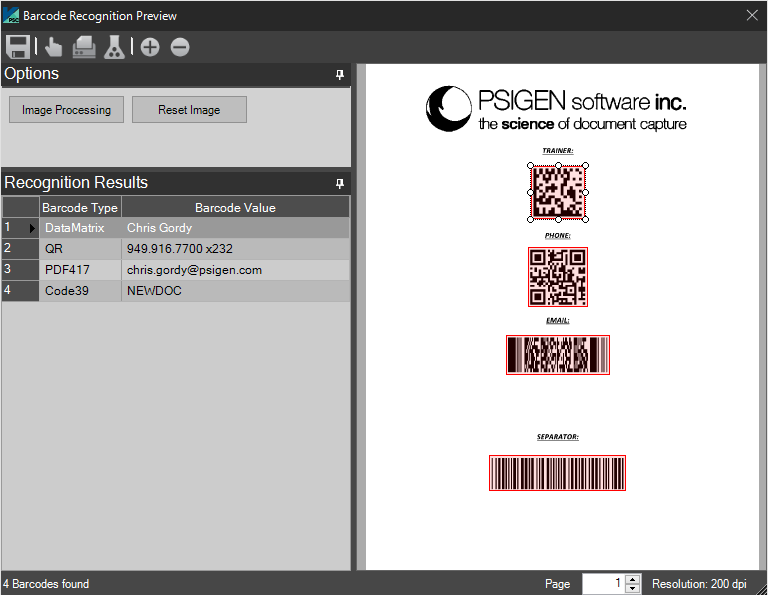
Define Zones
Select this to define a new zone.

Zoom in to the desired area leaving room to maneuver. Then select the draw zones Icon and draw the zone(s). Name the zone and fill out which page of the document it is expected to be found on. The Zone Names are kept in a list for use anywhere in the program that the user can Define Zones. NOTE: The Page of the template and resolution is displayed at the bottom of the screen and they MUST match the page and resolution at capture time.
![]() - delete the highlighted unwanted zone. Note: If a Zone is in use by any Capture Profile, the zone cannot be deleted.
- delete the highlighted unwanted zone. Note: If a Zone is in use by any Capture Profile, the zone cannot be deleted.
![]() - ungroup a cluster of child zones contained within the selected zone (child zones are used for OMR purposes).
- ungroup a cluster of child zones contained within the selected zone (child zones are used for OMR purposes).
Barcode Type
The following barcode font types are supported: 2 0f 5 Inverted, Australia Post, Aztec, BCD Matrix, Codabar, Code 128, Code 32, Code 39, Code 93, Datamatrix, EAN-13, EAN-8, GS1-128 (UCC/EAN-128), IATA 2 of 5, Industrial 2 of 5, Intelligent Mail, Interleaved 2 of 5, Matrix 2 of 5, PDF 417, Plus 2, Plus 5, Postnet, QR Code, Royal Mail (RM4SCC), UPC-A, and UPC-E.
Barcode Parsing
The user may select to populate the field with the entire contents (default) of the selected barcode or to populate the field with a subset of the barcode. If a subset of the barcode is specified, select the Start Position and End Position of the characters in the barcode to be placed in the current field.
NOTE: If the barcodes in question do NOT contain fixed length values an unexpected result will occur. See Barcode Splitting in the Capture Profile Configuration\Recognition\Barcode Detection section of this Manual for other options or use Scripting.

Populate field with entire barcode
The entire barcode value will be placed in the index field.
Populate field with subset of barcode
The value to be placed in the index field will be positional based on what is set in the Start Position and the End Position. In this example only the first 4 characters of the file name would be placed there.
Use Barcode Processing Script
Use script to extract specific data from barcodes that are inconsistent in length and/or content. Click “Edit” to bring up the Script Editor.
For more information on scripting please see the scripting section of this Administrators Manual.
NOTE: Scripting within PSIcapture requires knowledge of the C# programming language.
Generic example script

Document Index Fields: List
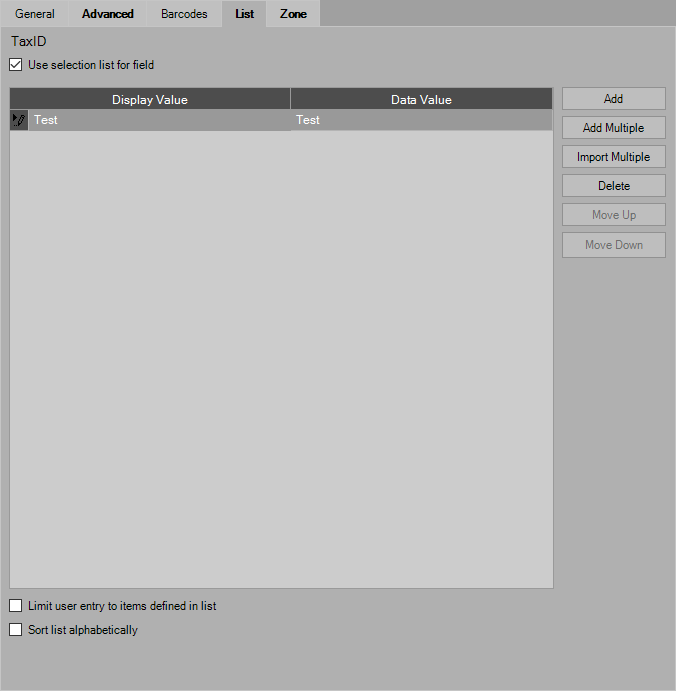
List Definition
Select the “Use selection list for field” option to create a specific list of values for the highlighted index field. These values can be used during the indexing process to populate the index field.
Add
Select the Add button to add a new value to the list. The user can specify separate display and data values for each entry. The Display Value is the “friendly name” for the item, which is displayed to the user in the list. The Data Value is the value that is stored and passed on to lookups, migrations, etc.
Add Multiple
The Add Multiple button displays a dialog screen where the user can enter multiple display and data entries in comma-separated value (CSV) format. Enter one new Display Value/Data Value pair per line, separated by a comma. For additional information regarding format, press the Help button. To add the entries to the List Definition, press the Save button. To abandon the entries without saving, press the Close button.
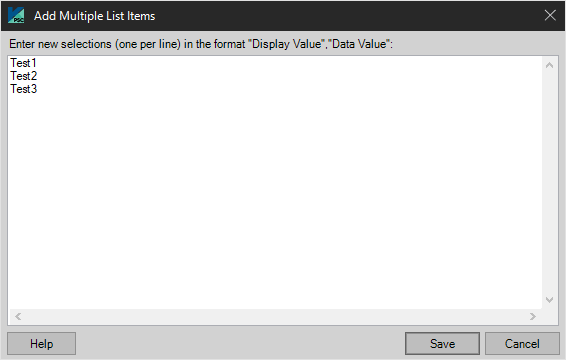
Import Multiple
Press the Import Multiple button to display a standard Windows File Open dialog screen which allows the user to select a pre-existing, comma separated file containing new Display Value/Data Value pairs.
Delete
Select a list entry and press Delete to remove it from the list.
Move Up/Down
Select a list entry and press up or down to change its position in the.
Limit user entry to items defined in list
Select this option to prevent users from entering values during indexing that are not in the pre-defined list.
Sort list alphabetically
Select this feature to display the Display Values in alphabetical order during indexing.
NOTE: List boxes automatically support type ahead. For large lists or lists that change frequently, use the Lookups function in Capture Profile Configuration/Advanced Indexing.
Document Index Fields: Zone
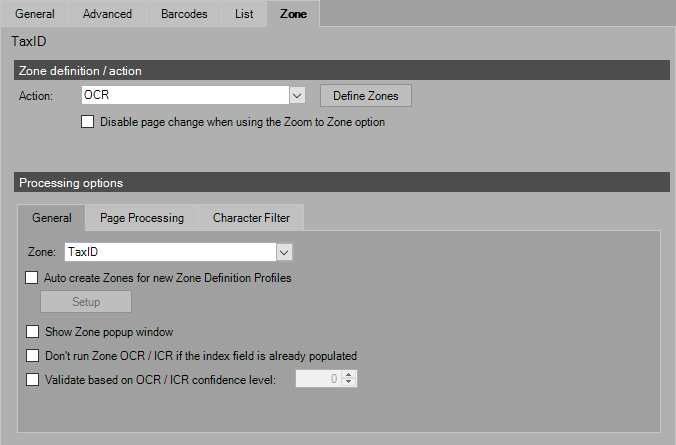
NOTE: Although OMR or OCR zones may be defined on the folder index fields they are only processed on the folder separator sheet. Conversely OMR or OCR may occur on any image within the document.
Zone Definition / Actions:
- None
- Zoom Only (No Recognition)
- OCR – Optical Character Recognition
- ICR – Intelligent Character Recognition (Handwriting)
- OMR – Optical Mark Recognition
- MICR - Magnetic Ink Character Recognition Code font detection
- On Demand OCR/ICR Only
Action: None
No zone related functions are performed.
Action: Zoom Only (No Recognition)

No recognition will be performed on the defined zone. However, when the user selects the index field box in the Capture and Index modules or in the QA module if defined and the feature “Zoom to zone for index fields with zones defined” is select in the Quality Assurance Settings configuration screens, the document will automatically zoom into the defined zone. This can be helpful during manual indexing to make text easier to read. This can also be described as a Zoom Assisted Key from Image Capability.
Choose a zone name from the “Zone” drop down list or select Define Zones to define a new zone.
Disable page change for Zoom Only Zones
Prevents the viewer from changing the page when this index field becomes active
Auto Create Zones for new Zone Definition Profiles
Allows zones to be created when a new Zone Definition Profile is triggered. For more information, see:
PSIcapture Administrator Guide: Auto Zone Creation Configuration
Action: OCR/ICR
Selecting this option will cause the OCR/ICR engine to attempt to OCR/ICR the contents of the selected zone and populate the index field for the current document. This process will occur either during auto-indexing or when the field is selected during manually indexing.
NOTE: Zone OCR/ICR if defined for Folder fields runs on the Folder Separator Sheet ONLY.
Zone OCR/ICR Options: General

Zone
Choose a zone name from the “Zone” drop down list or select Define Zones to define a new zone.
Show Zone Popup Window when Indexing
Selecting this option causes a floating popup window to appear when indexing is active in the product.
Don’t run Zone OCR if field is already populated
Skip OCR/ICR if there is already data in the index field.
Validate based on OCR/ICR confidence level
Check this option to enable validation based on a minimum OCR/ICR confidence level, and specify the minimum level excepted. If the results fall under this percentage, the value will be flagged as invalid during indexing.
Page Processing Option
Choose pages from the document for the recognition engine to process. Select from Defined Page, First Page, Last Page, or All Pages.
Skip Document Separator/Skip Folder Separator
Choose to skip the document or folder separator pages.
Zone OCR/ICR Options: Page Processing
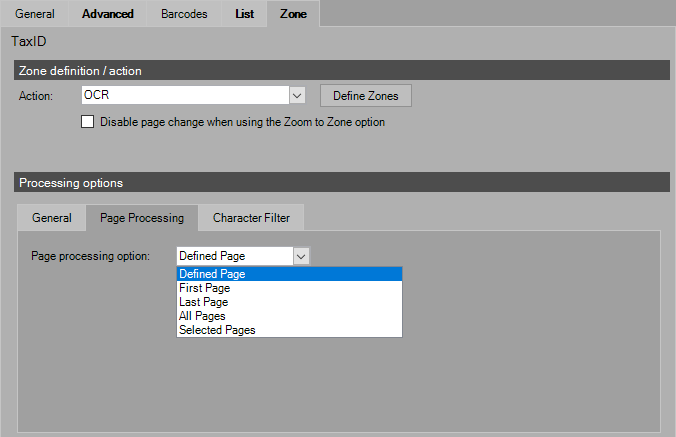
Page Processing Option - Choose which page to process: Defined Page, First Page, Last Page, All Pages, or Selected Pages.
Zone OCR/ICR Options: Character Filtering

Character Filter
If a zone is known to contain either only numeric or only alpha characters, the OCR results can be filtered to return only those characters by specifying that option in the Filter. If the OCR text contains both alpha and numeric characters, then set this to All Characters. Some possible options are All Characters, Alpha Only, Numeric Only, Numeric Extended (0-9,$,%,#,+,- ..), Date (0-9./-), Extended Characters Only, and Standard Printable Characters.
Enable Extended Characters
This setting allows user to include additional characters that would not have been included based on the Character Filter option selected above. For instance, if the user has a zone that contains numeric characters and the letters A, B, and C the user may set the Character Filter to Numeric Characters Only, Enable Extended Characters, and add A, B, and C into the Extended Characters List. By doing this, there will be better OCR results than if the user had simply set the Character Filter to ‘All Characters’.
Click “Enter Characters” to add characters to the character filter.
Invalid Character Action
Do Not Correct
This populates with all characters detected by the OCR/ICR engine. There may be chances for inaccuracies.
Remove
All invalid characters as chosen from the character filter will be deleted from the return value.
Auto Correct
This option will find and replace all invalid characters with user specified characters defined in the following list:
Auto Correction Settings
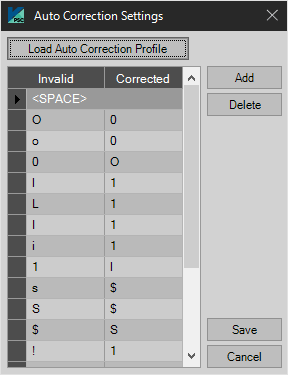
The user can Add or Remove settings to enhance the quality of the OCR. For example in the table above if the OCR engine returns an alpha O and the Character Filter + Extended Characters are expecting 0-9 and a, b or c. The character placed in the field would be a zero (0).
Replace with Marker
Invalid Character Marking
Choose a valid character to put in place of an invalid character that has been deleted. NOTE: Replacing invalid characters with a character that is invalid for that fields data type will cause either no data to be returned or errors to occur. (ie). an asterisk (*) when the fields data type is numeric.
Character Filtering Processing
Choose to filter the entire OCR/ICR zone or only on certain matching words when detected.
Action: OMR
Choose a zone name from the “Zone” drop down list or select Define Zones to define a new zone. NOTE: For folder fields the template must be a part of the folder separator sheet.
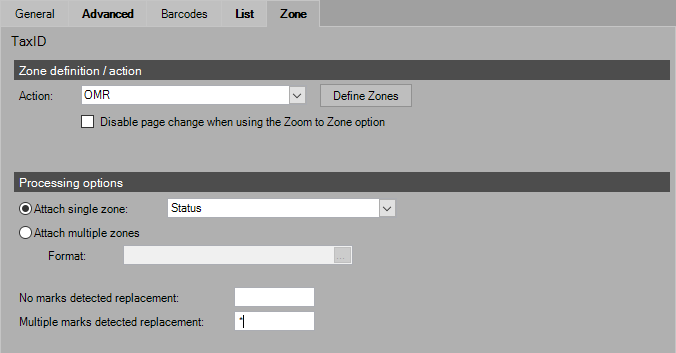
Zone OMR Processing Options
Attach Single Zone
Select from the previously defined zones.
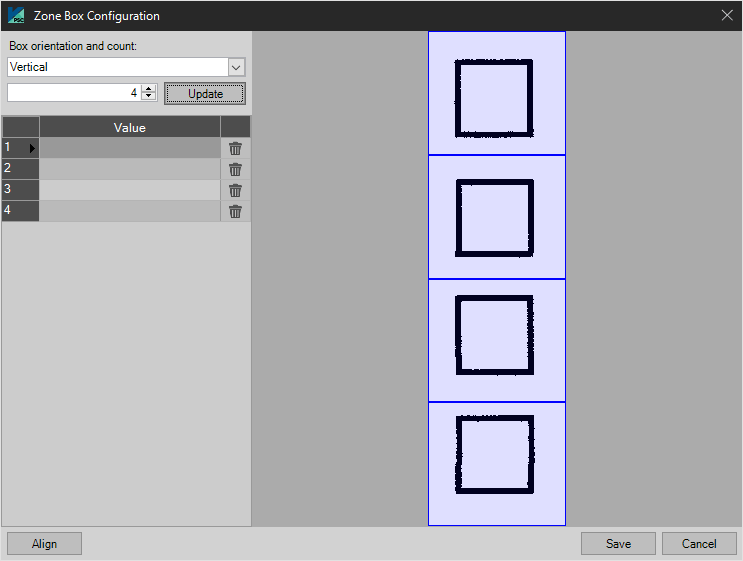
Attaching the OMR zone to the Index Field will populate the field with the value of the zone with the highest weight of fill.
Select which Zone you'd like to use from the drop down next to "Attach Single Zone".
Attach Multiple Zones
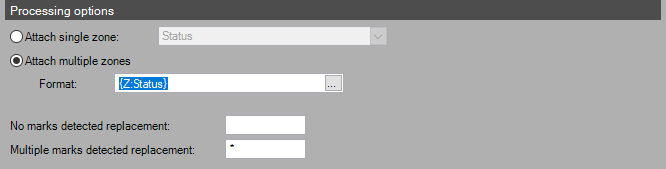
When the user then selects the Ellipses (...) to the right of the "Format" field, the following dialog appears:
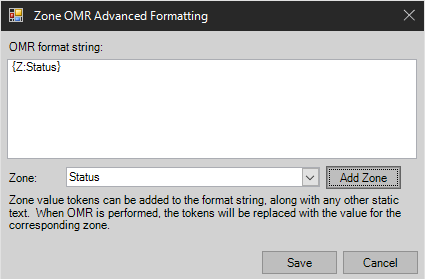
Add Zone in Zone OMR Advanced Formatting
Select from the previously defined zones in the order in which concatenation is desired.
Below is a look at previously defined zones.

Replacement Values
No Mark Detected
Define a character to populate a field when no mark is detected (default is *). Manual indexing is needed for these type of documents.
Multiple Mark Detected
Define a character to populate a field when multiple marks are detected (default is *). Manual indexing is needed for these types of documents. NOTE: It is critical that the template is BLANK (without marks) as base weights are assigned when selecting save in the define zone screen.
Action: On Demand OCR/ICR Only
Also known as rubber band OCR or drag and drop OCR; selecting this option will cause the OCR/ICR engine to attempt to OCR/ICR the contents of the area drawn by the user during manual indexing and populate the index field. NOTE: There is no need to define the zone for this function because the zone will be hand drawn during manual indexing, as shown in the example below:

On Demand OCR/ICR Only: Character Filtering
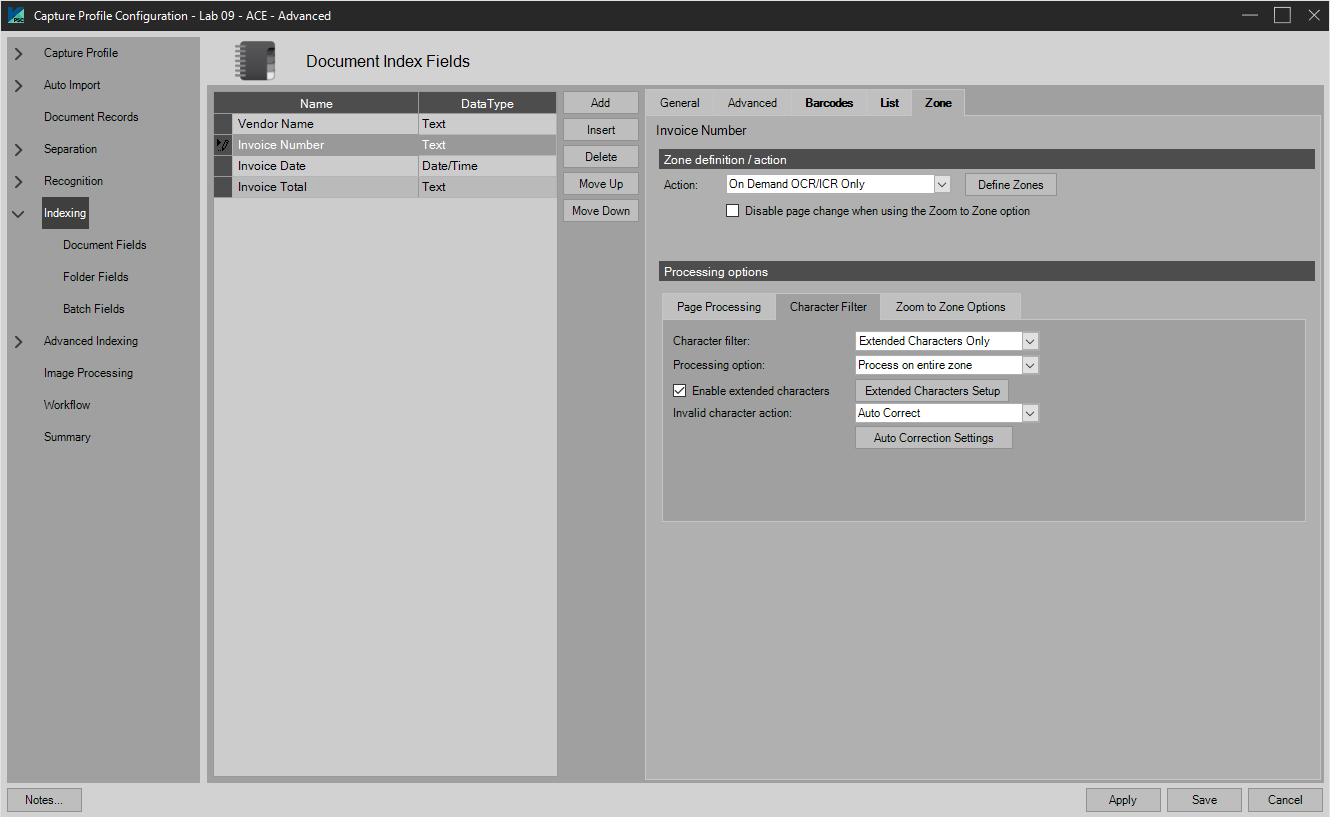
Character Filter
If a zone is known to contain either only numeric or only alpha characters, the OCR results can be filtered to return only those characters by specifying that option in the filter. If the OCR text contains both alpha and numeric characters, then set this to All Characters. Some possible options are All Characters, Alpha Only, Numeric Only, Numeric Extended (0-9,$,%,#,+,- ..), Date (0-9./-) and Extended Characters Only, Standard Printable Characters.
Enable Extended Characters
This setting allows user to include additional characters that would not have been included based on the Character Filter option selected above. For instance, if the user has a zone that contains numeric characters and the letters A, B, and C the user may set the Character Filter to Numeric Characters Only, Enable Extended Characters, and add A, B, and C into the Extended Characters List. By doing this, there will be better OCR results than if the user had simply set the Character Filter to ‘All Characters’.
Click “Enter Characters” to add characters to the character filter.
Enter each individual extended character to the list.
For example, If users wanted all Letters and Numbers, users should select “Alpha Only” and then enter “1234567890” into the extended characters list.
Invalid Character Action
Do Not Correct
This will populates with all characters detected by the OCR/ICR engine. There may be chances for inaccuracies.
Remove
All invalid characters as chosen from the character filter will be deleted from the return value.
Auto Correct
This option will find and replace all invalid characters with user specified characters defined in the following list:
Auto Correction Settings
The user can Add or Remove settings to enhance the quality of the OCR. For example in the table above if the OCR engine returns an alpha O and the Character Filter + Extended Characters are expecting 0-9 and a, b or c. The character placed in the field would be a zero (0).
Replace with Marker
Invalid Character Marking
Choose a valid character to put in place of an invalid character that has been deleted. NOTE: replacing invalid characters with a character that is invalid for that fields data type will cause either no data to be returned or errors to occur. (ie). an * when the fields data type is numeric.
Character Filtering Processing
Choose to filter the entire OCR/ICR area or only on certain matching words when detected.
When a user selects "Define Zone" via a relevant selection above, the Zone Configuration section appears:
Zone Configuration - General
Select this to define a new zone.
The Icons at the top of the above screen allow the user to:
 |
Save Zone Profiles - saves the zone settings for the current profile | |
 |
Select Profile - Opens the profile the user wants to use for zone configuration. When the selection window popups, users have the ability to import and export Zone Definition Profiles as show in the screenshot below.
|
|
 |
New Profile - Creates a new, blank Zone profile for editing. | |
 |
Copy Current Profile - Enables user to duplicate profiles for other documents by copying the currently edited profile. | |
 |
Delete Current Profile - Deletes the current profile open | |
 |
Select Template Image - load a template image for your currently edited profile. Supported image types are: TIF, TIFF, JPG, JPEG, JP2, PDF, PNG, BMP, GIF. | |
 |
Capture Template Image - allows user to capture a template image from a capture device | |
 |
Rerun Auto Zone Creation - no longer requires a new template image to be loaded each time it is to be used |
The following toolbar commands are available for Zone Creation above the Preview Panel
 |
Pointer – standard mouse pointer (selecting by default) | |
 |
Draw Zone (CTRL+1) – manually draw an OCR zone | |
 |
Draw OMR Zone (CTRL+2) – manually draw and OMR zone | |
 |
Draw Smart Zone (CTRL+3) – manually draw a smart zone | |
 |
Draw OMR Smart Zone (CTRL+4) – manually draw a smart OMR zone | |
 |
Draw Precision OMR Zone (CTRL+5) | |
 |
Auto Sized Zones – select from a list to draw a new zone on the described area. Users have the ability to define Dynamic Zones (i.e. Full Page, Bottom Half, etc.) that autosize based on the size of the image being processed. When adding a new Auto Sized Zone, user will be prompted on whether they want this to be a Dynamic zone or not.
If they want to change the dynamic zone setting on an existing zone, they can do so on the Document Fields.
NOTE: Dynamic zones are not limited to just zones created using the Auto Sized Zone menu. Any standard or smart zone can have the dynamic zone setting enabled. |
|
 |
Make Copy of Current Zone – repeat a zone (use this to make OMR configuration quick) | |
 |
Delete Selected Zones – deletes the selected zones (NOTE: Users can use the delete key on their keyboard to delete selected zone) | |
|
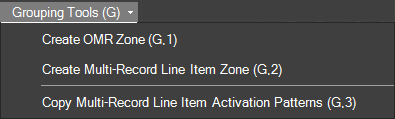
Grouping Tools – group multiple zones for OMR purposes. Select Create OMR Zone or Create Multi-Record Line Item Zone |
||
 |
Zone Display – allows user to select which zones to show, either All Zones or Selected Zone. |
|
 |
Selection Zoom – Select an area to zoom |
|
 |
Zoom In / Out – increase / decrease the size of the image |
|
 |
Rotate Left / Right – rotate document image left |

Zone Definition Profile

Name - Enter a unique name for the zone definition profile
Description - Enter a description for the zone definition profile
Trigger Settings (Trigger) - Choose when to trigger the definition profile during capture
- No Zone Definition Profile Trigger
- Activate on Record Type
- Activate on Classification Form ID
- Activate on Page Orientation
- Activate on script
Zones Panel
Zoom in to the desired area leaving room to maneuver. Then select the draw zones Icon and draw the zone. Users can double-click a drawn zone to edit its anchors and child zones, or in PSIcapture 7.7+, users can select the "Edit" button.

Zone Name, Page, and Toolbar

Name the zone and fill out which page of the document it is expected to be found on. The Zone Names are kept in a list for use anywhere in the program that the user can Define Zones. Users can view via the dropdown names of mapped Index Fields when creating a new field.
NOTE: The Page of the template and its Resolution is displayed at the bottom of the screen and they MUST match the page and resolution at capture time.
|
Edit Zone - Brings up the Zone Configuration dialog and allows editing of child zones, anchors, etc. Further details explored in the next section. Note: This button is only available in PSIcapture 7.7+ |
||
| Delete Zone - delete the highlighted unwanted zone. Note: If a Zone is in use by any Capture Profile, the zone cannot be deleted. | ||
| Image Processing - apply image processing to the zone template image. | ||
| Zone Preview - preview OCR results on printed text in the selected zone. | ||
| Ungroup Child Zones - ungroup a cluster of child zones contained of the selected zone (child zones are used for OMR purposes). | ||
|
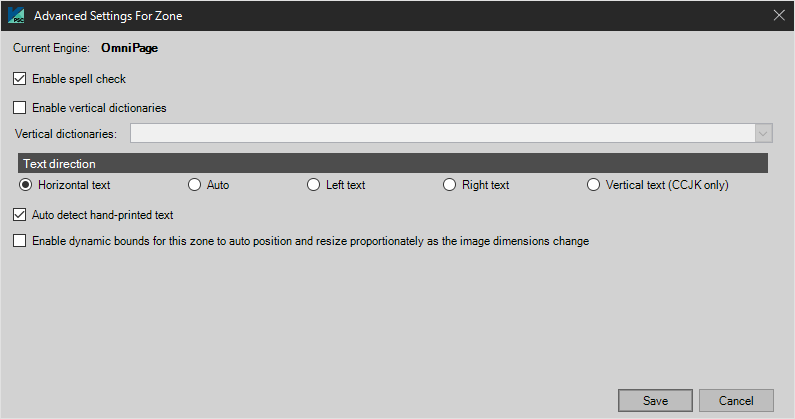
Advanced Settings for OmniPage Engine:
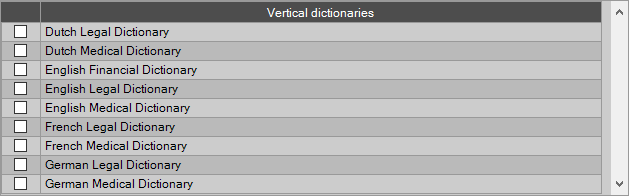
Enable Spell Check Enable Spell Check is a feature to account for "everyday norms" when generating results. For example, spell check ensures a number of such as 34567 would not be read as 34S67, as it is unlikely that the letter "S" would appear within a list of numbers. If your images are of high quality (computer generated) and a zone contains data that breaks everyday norms (in the example above, contains letters and numbers) disable this option for the zone to improve your OCR results. Enable Vertical Dictionaries Vertical dictionaries are seen in the legal, medical, and financial fields, and the OmniPage engine supports several languages with vertical orientations, including the ones listed in this screenshot:
Text Direction Specify the direction of the text for the OmniPage OCR engine to read from, including:
Auto-Detect Hand-printed text (ICR) The OmniPage engine will automatically detect hand-printed text (ICR) and adjust recognition settings accordingly. This feature is an enhanced version of the legacy feature "Machine Print Font Type - Unknown". Only subregions classified as machine print will be further processed. Hence, there is some risk that low-quality machine print subregions are missing in the final result, for they might have erroneously been classified as handwriting. Enable Dynamic Bounds for this zone to auto position and resize proportionately as the image dimensions change Check this option to automatically resize zones based on the dimensions of the captured page. For example, if a zone is defined to encompass the top half of an 8.5” x 11” page, and an 8.5” x 5” page is captured, the zone’s height will automatically be adjusted to cover only the top half of the page.
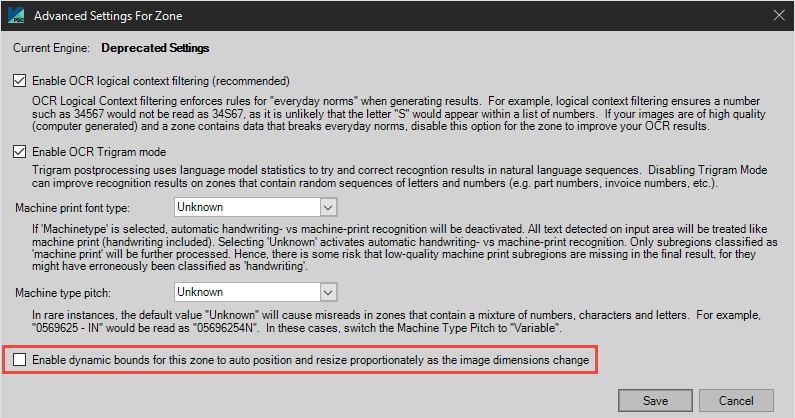
Advanced Settings for RecoStar (Deprecated) Engine:
Enable OCR Logical Context Filtering (Recommended) OCR Logical Context filtering enforces rules for "everyday norms" when generating results. For example, logical context filtering ensures a number of such as 34567 would not be read as 34S67, as it is unlikely that the letter "S" would appear within a list of numbers. If your images are of high quality (computer generated) and a zone contains data that breaks everyday norms (in the example above, contains letters and numbers), disable this option for the zone to improve your OCR results. Enable OCR Trigram Mode Trigram postprocessing uses language model statistics to try and correct recognition results in natural language sequences. Disabling Trigram Mode can improve recognition results on zones that contain random sequences of letters and numbers (e.g. part numbers, invoice numbers, etc.). Machine Print Font Type User options include Unknown and Machine Type. If Machine Type is selected, automatic handwriting vs. machine-print recognition will be deactivated. All text detected on input area will be treated like matchine print (handwriting included). Selecting Unknown activates automatic handwriting vs. machine print recognition. Only subregions classified as machine print will be further processed. Hence, there is some risk that low-quality machine print subregions are missing in the final result, for they might have erroneously been classified as handwriting. Machine Type Pitch User options include Unknown and Variable. In rare instances, the default value Unknown will cause misreads in zones that contain a mixture of numbers, characters, and letters. For example, "0569625-IN" would be read as "05696254N". In these cases, switch the Machine Type Pitch to Variable. Enable Dynamic Bounds Check this option to automatically resize zones based on the dimensions of the captured page. For example, if a zone is defined to encompass the top half of an 8.5” x 11” page, and an 8.5” x 5” page is captured, the zone’s height will automatically be adjusted to cover only the top half of the page. |
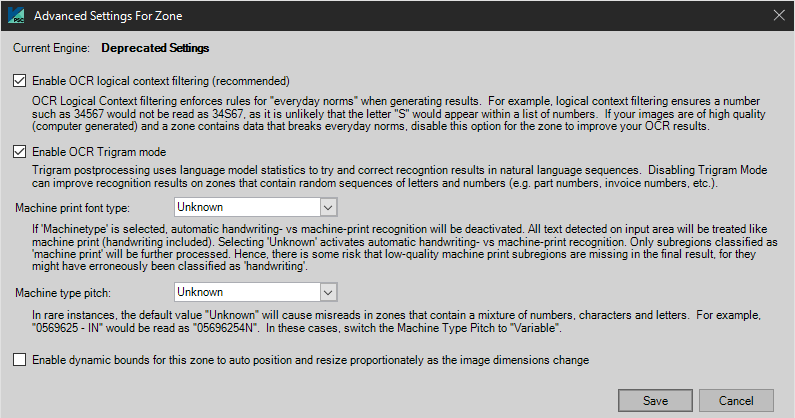
Zone Configuration - Edit Zone
For a full breakdown of the Zone Editing process, see:
PSIcapture Administrator Guide: Capture Profile: Indexing: OCR Smart Zone Configuration
Zone Configuration - Anchoring
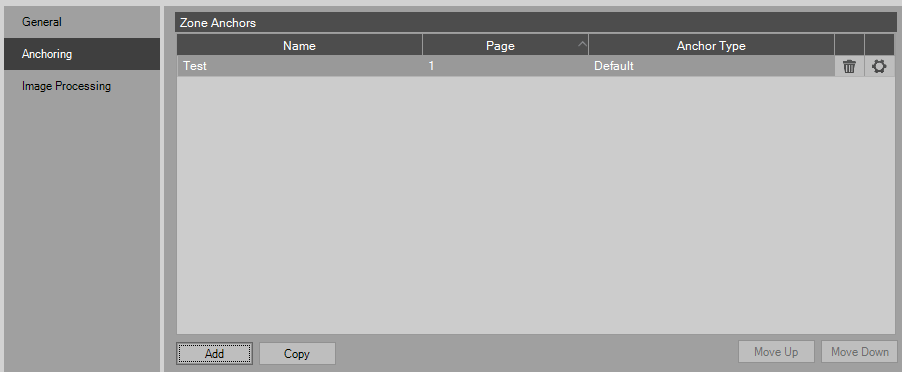
Select Add to create an anchor
Anchor Name - A unique name to identify the anchor
Process Anchor On All Pages - Check this box if the user wants to use this anchor on all the pages of the batch.
Anchoring Type - The following anchor types are available for use:
- Default (Top Left of Page)
- Page Image to use for Anchoring - Main Image, Original Image, Alternate Image
- Alternate Image Tag
- Fixed Point
- Page Image to use for Anchoring - Main Image, Original Image, Alternate Image
- Alternate Image Tag
- Anchor Point - Define the position of the Anchor Point
- Barcode - choose the barcode type and pattern (must match)
- Page Image to use for Anchoring - Main Image, Original Image, Alternate Image
- Alternate Image Tag
- Barcode Type - Select from the list of supported barcode types.
- Barcode Pattern
- Preview
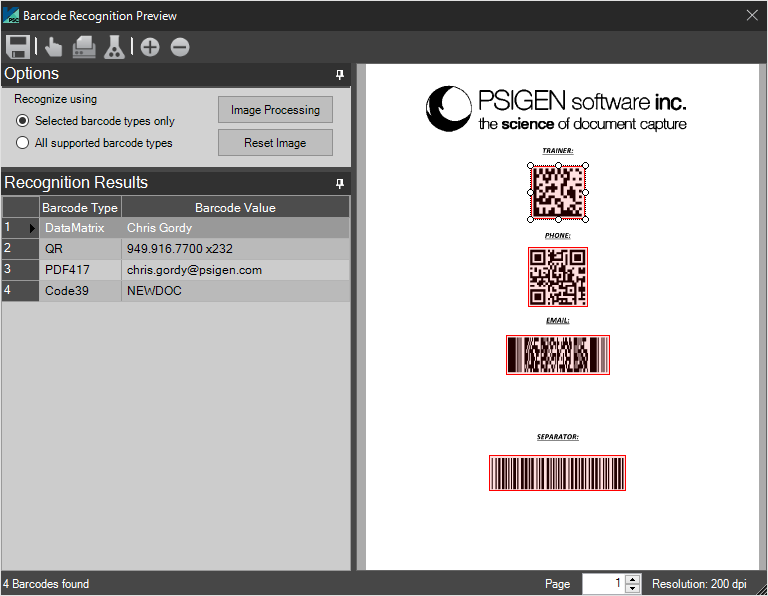
Options - Recognize using:
One of the previously selected barcode types from the previous screen.
All supported barcode types. Without selecting a barcode type, the detected barcodes will be prompted to be automatically selected on the next screen.
- Patch Code
- Page Image to use for Anchoring - Main Image, Original Image, Alternate Image
- Alternate Image Tag
- Patch Code Type - Select from the list of supported Patch Code types:
- Patch II
- Patch III
- Patch T
- Patch Code Number
- Zone OCR Expression
- Page Image to use for Anchoring - Main Image, Original Image, Alternate Image
- Alternate Image Tag
- Zone OCR Text
- Zone to Search Anchor For
- <Entire Page>
- Other options include current configured zones
- Precision OMR Time Tracks
- Page Image to use for Anchoring - Main Image, Original Image, Alternate Image
- Alternate Image Tag
Zone Configuration - Image Processing
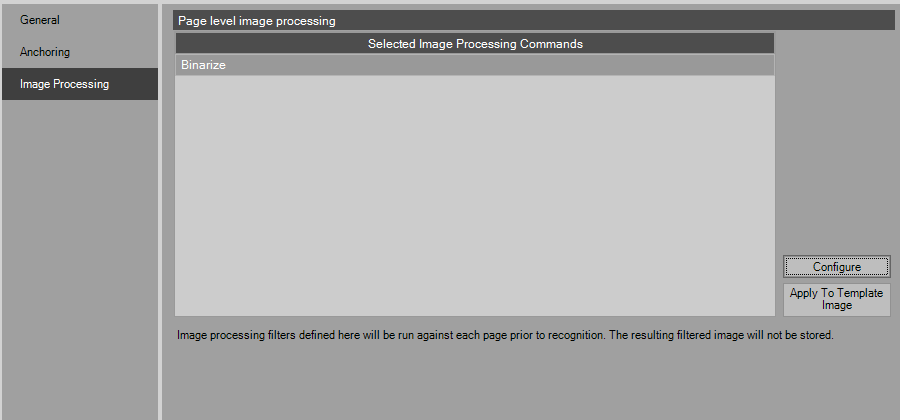
Select Configure to add image processing to the template document. For more details on the image processing options, see:
PSIcapture Administrator Guide: Image Processing
For more information on configuration Smart Zones vs. Standard Zones, see:
PSIcapture Administrator Guide: Capture Profile: Indexing: OCR Smart Zone Configuration
Comments
Article is closed for comments.