| version 7.9.x | Download Pending |
Audience
This article is intended for PSIcapture Administrators.
Overview
The PSIcapture OCR Workflow step allows Administrators to OCR the content of specific documents within a workflow and then attach or migrate that OCR data as needed. To begin, Administrators must add an OCR workflow step to their capture profile. Once added, when clicking "Configure" on the OCR Workflow step, the following screen appears:

The OCR Workflow configuration options specify the precise behavior of the OCR module as it executes through the workflow of the chosen Capture Profile. The OCR module also is used to convert image files from TIFF to PDF format, in short behaving like a PDF maker.
General Tab
The options available on the General tab of OCR settings are outlined below.
OCR Engine Options

- OCR Engine
- Omnipage - OmniPage is now the OCR engine by default. This engine has the ability to recognize hand print as well as machine printed text.
- Deprecated Settings - The RecoStar OCR engine is now deprecated. When this engine is used, the setting "Enable Spell Check" below is then changed to "Enable Logical Context Corrections".
- Enable Image Pre-processing – If image processing has not been performed in earlier steps. This lets the user do things like deskew, despeckle, resize, smoothing, auto orient, etc. These options can be configured in Capture Profile – Image Processing. PSIcapture will run any items in the section when running OCR for this Capture Profile.
- Enable Auto Rotation – If for any reason the pages in a document are upside down or not facing the right direction, this enables PSIcapture to automatically rotate if this didn’t happen in previous steps. This could potentially improve OCR accuracy.
- Enable Spell Check - This feature uses the context of the surrounding characters to perform a spell check and attempt to match to a corresponding correct word.
- NOTE: This feature is called "Enable Logical Context Corrections" when the Deprecated Settings (RecoStar OCR Engine) option is selected.

- NOTE: This feature is called "Enable Logical Context Corrections" when the Deprecated Settings (RecoStar OCR Engine) option is selected.
Output Options
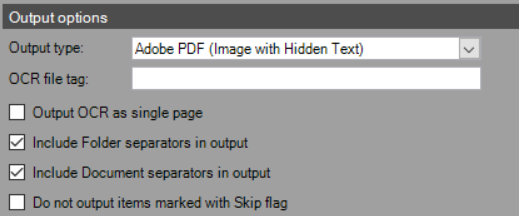
- Output Type – Choose which document type to use when outputting captured images.
- Adobe PDF (Image Only) – Converts TIFF images to PDF without performing OCR.
- Adobe PDF (Image with Hidden Text) – Performs OCR on the document and includes the data as hidden text within the PDF.
- Text – Performs OCR on the document and outputs ONLY a text file with the OCR results.
- XML – Performs OCR on the document and outputs ONLY a XML file with the OCR results.
- OCR File Tag – Enter a tag to associate with the outputted document.
- Output OCR as Single Page – Selecting this option produces each image as a single page PDF. NOTE: By default PSIcapture outputs a multi-page file.
- Include Folder Separators in Output – Use this option to include or exclude the folder separator page in the outputted file. This is useful if by leaving this option unchecked the folder separator page would be available in the QA or Index Module but not in the final output file.
- Include Document Separators in Output – Use this option to include or exclude the document separator page in the outputted file.
- Do Not Output Items Marked with Skip Flag – Any page/document/folder tagged with a skip flag will not be included in the outputted file.
Secondary Output Options

- Enable Secondary Output – Checking this box means the user needs and additional type of document when outputting.
- Secondary Output Type - Choose which additional document type to use when outputting captured images.
- Adobe PDF (Image Only) - Converts TIFF images to PDF without performing OCR.
- Adobe PDF (Image with Hidden Text) – Performs OCR on the document and includes the data as hidden text within the PDF.
- Text – Performs OCR on the document and outputs ONLY a text file with the OCR results.
- XML – Performs OCR on the document and outputs ONLY a XML file with the OCR results.
- Secondary OCR File Tag - Enter an additional tag to associate with the additional outputted document
User Dictionary
Enable Checking Using User Dictionary – Check this box and click on Setup to enter any words to be used in the User Dictionary. This may be helpful when performing OCR on specialized documents such as medical documents.
PDF Options
The options available on the PDF Options tab of OCR settings are outlined below.
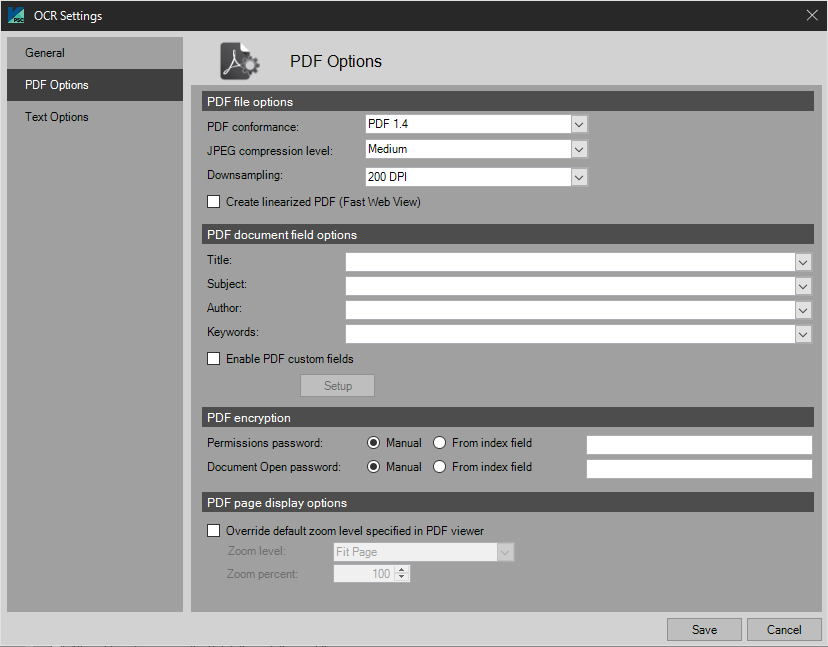
PDF File Options
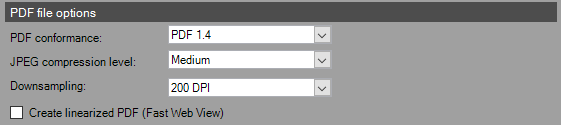
- PDF Conformance – Choose what type of PDF to output.
- PDF 1.4
- PDF 1.5+
- PDF/A-1b
- JPEG Compression Level – Select which compression level to output. The higher the compression the better the output.
- None
- Low
- Medium
- High
- Maximum
- Downsampling – Choose the DPI for the output file. The higher the DPI (Dots Per Inch) the clearer the image will appear. Downsampling the DPI will allow for smaller file sizes.
- Original
- 100 DPI
- 125 DPI
- 150 DPI
- 175 DPI
- 200 DPI
- 225 DPI
- 250 DPI
- 275 DPI
- Create Linearized PDF (Fast Web View) – This optimizes the output file for web view and decreases the file size.
PDF Document Field Options
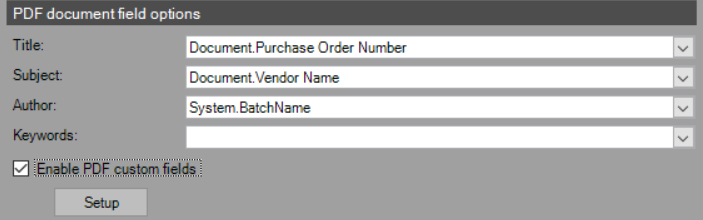
The standard PDF document fields are listed below. The user can select any system, batch, folder or document index field to populate the desired PDF document fields inside the created PDF file.
- Title
- Subject
- Author
- Keywords
- Enable PDF Custom Fields – With this box checked the Setup button is enabled. The Setup button pops up a window with the custom fields available. Select the checkbox in the Include column to place both the Field Name of that row and its corresponding data value in the custom tab of a PDF properties when viewing from the local file explorer. Click on Save to confirm the settings.
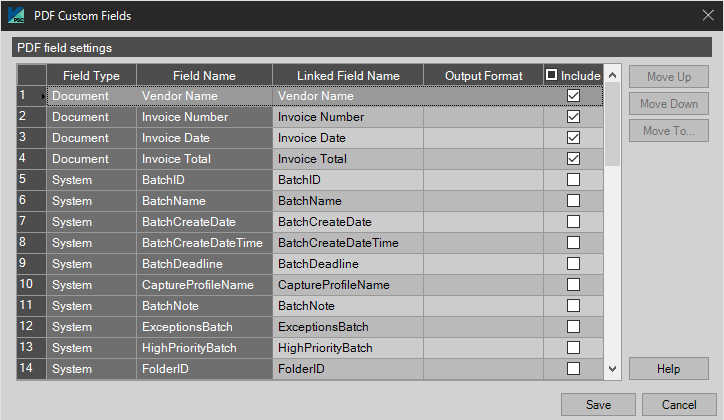
- Move To – This option will select the specified row within PDF Custom Fields setup and is useful when working with a large number of data fields.
PDF Encryption

Users can set passwords for the PDF documents outputted.
- Owner Password
- User Password
PDF Page Display Options

- Override Default Zoom Level Specified in PDF Viewer
- Zoom Level
- Fit Page
- Fit Width
- Fit Height
- Zoom Percent
- Zoom Percent - Enter the percent of zoom to start on when in the PDF Viewer.
Text Options
The options available on the Text Options tab of OCR settings are outlined below.
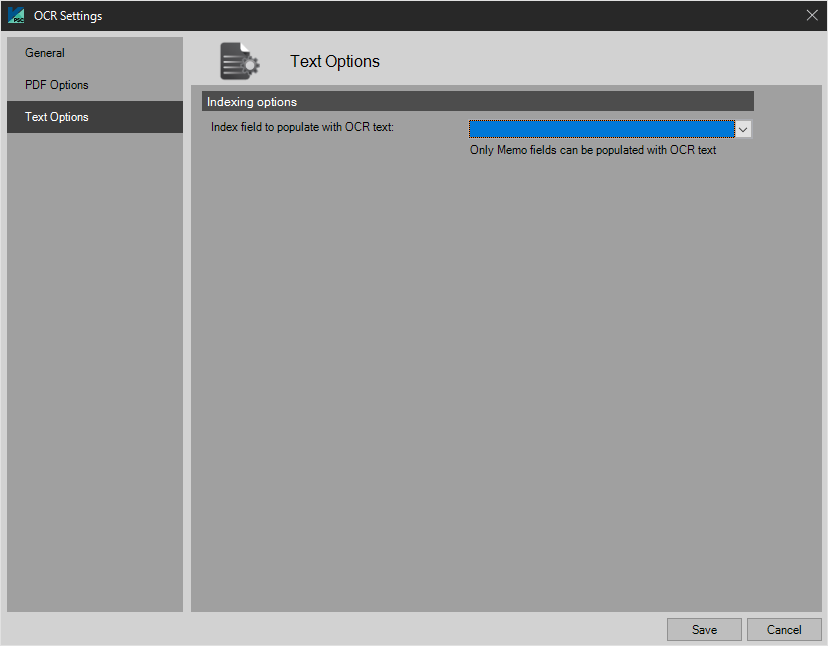
Indexing Options
- Index Field to Populate with OCR Text - Here the user can pick from any memo index fields setup in Capture Profile - Indexing. The OCR text captured will populate the selected memo index field. NOTE: Only memo fields can be populated with OCR text.
For more information on the user experience with a PSIcapture OCR Workflow step, see:
Comments
Article is closed for comments.