| version 7.9.x | Download Pending |
Note
This article includes advanced Administrator areas for PSIcapture as well as Alchemy's Web Portal.
Audience
This article is meant for PSIcapture Administrators.
Overview
The Alchemy Web Engine Migration allows users to migrate content from PSIcapture to Alchemy's platform, with a wide variety of configuration options. Below is a breakdown of configuration options available in this migration, and how to link those elements to your Alchemy configuration.
Alchemy Web Engine General Settings Tab
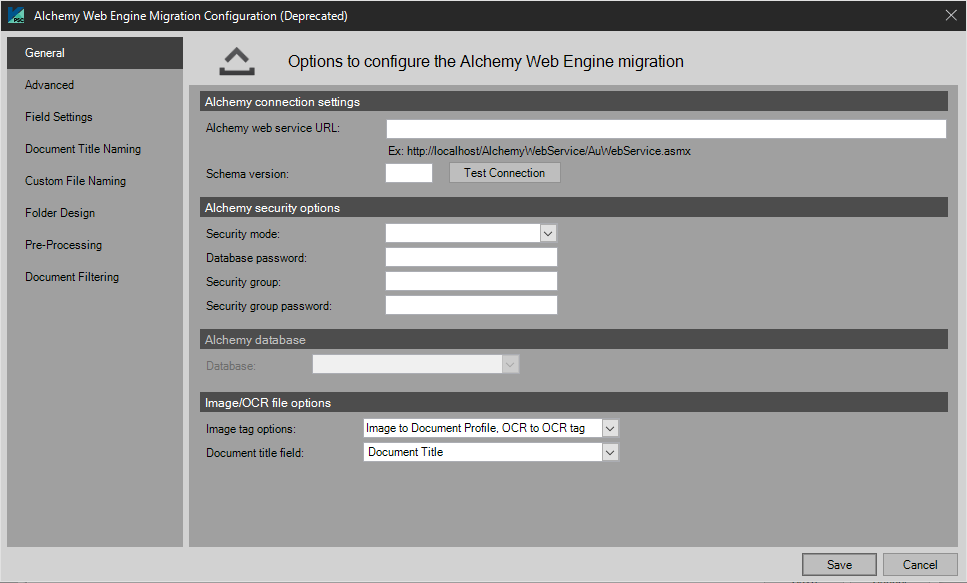
Alchemy Connection Settings
Alchemy Web Service URL
Web address for the Alchemy Web service
Schema Version
Enter Schema version in the box provided.
Test Connection
Click on Test Connection to validate the Database/Security Group combinations are correct and work.
Security Options
Security Mode
Choose between:
- None
- DB
- SG
- EN
- EG
- IS
Database Password
Enter the corresponding password for the Database selected.
Security Group
Enter the Security Group if any for the Database selected.
Security Group Password
Enter the Security Group Password if any for the Security Group associated with the Database selected.
Alchemy Database
Choose from database list.
Image/OCR File Options
Image Tag Options
Select from the following options:
- Image to Document Profile, OCR to OCR tag
- Image to Document Profile, no OCR tag
- OCR to Document Profile, no OCR tag
Document Title Field
Supply the name of the Document Title Field or enter Document Title to use the information which the user selects in the Document Title Naming tab.
Advanced Migration Settings
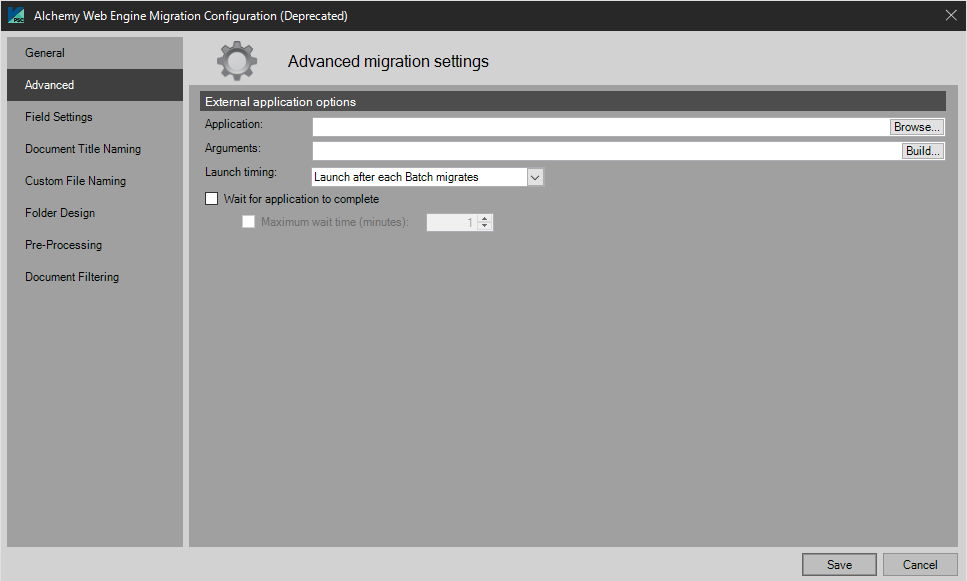
External Application Options
The user may wish to execute another windows application as a part of this migration. In order to accomplish this, the user must configure the following:
Application to Launch
Select the windows executable to launch.
Application Arguments
Supply any command line arguments, if any. These are supplied by the executable’ developer.
Launch Timing
The user can choose between the following timing options to launch the executable:
- Launch application after each Batch is migrated
- Launch application after all selected Batches are migrated
Field Settings
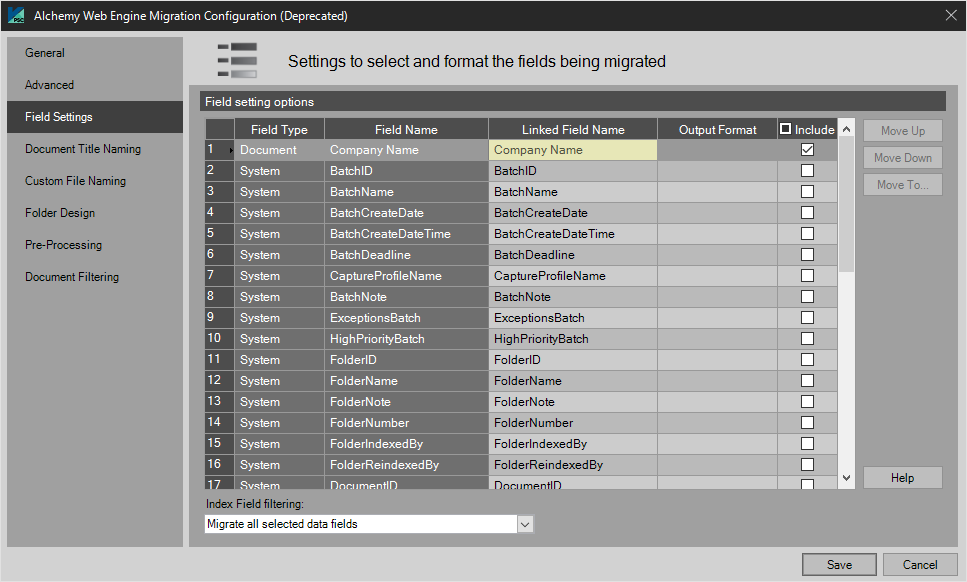
The Field Settings tab provides a tool to map index values from the capture process to index or metadata fields in Alchemy's Web Portal.
The Field Name column represents the index field name defined for this Document Type, while the Linked Field Name column represents the index field name in Alchemy.
The Output Format supports Text Field Masking.
To include a field to be migrated, select the corresponding checkbox in the "Include" column.
NOTE: If there are fields that do not match fields in the dropdown list they will be highlighted yellow.
Document Title Naming
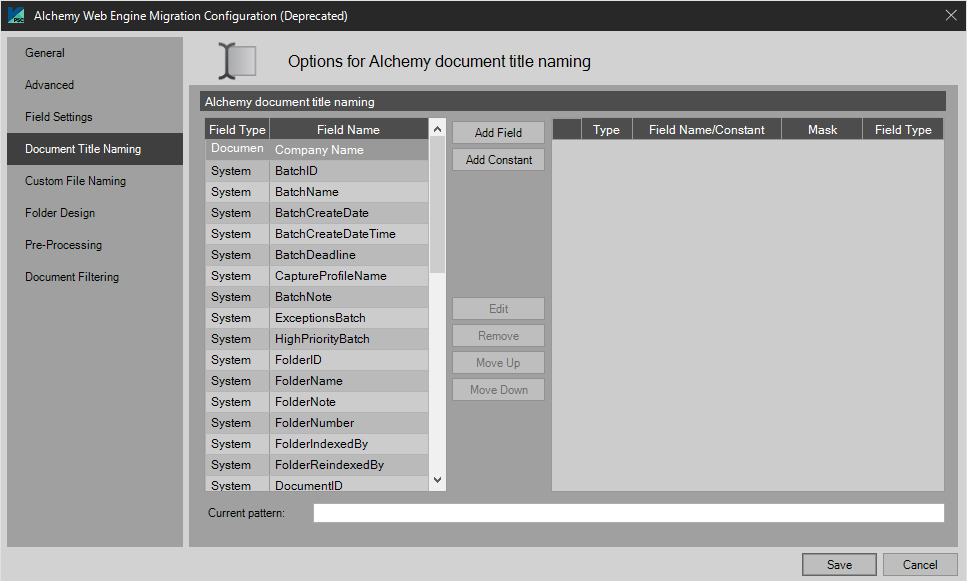
The Document Title Naming tab supports the use of system and index data in naming of the document titles that are being migrated to the target system.
Document Title Naming should be constructed initially by the Alchemy Administrator, and then that same design can be customized here to match your Alchemy organization scheme.
Custom File Naming
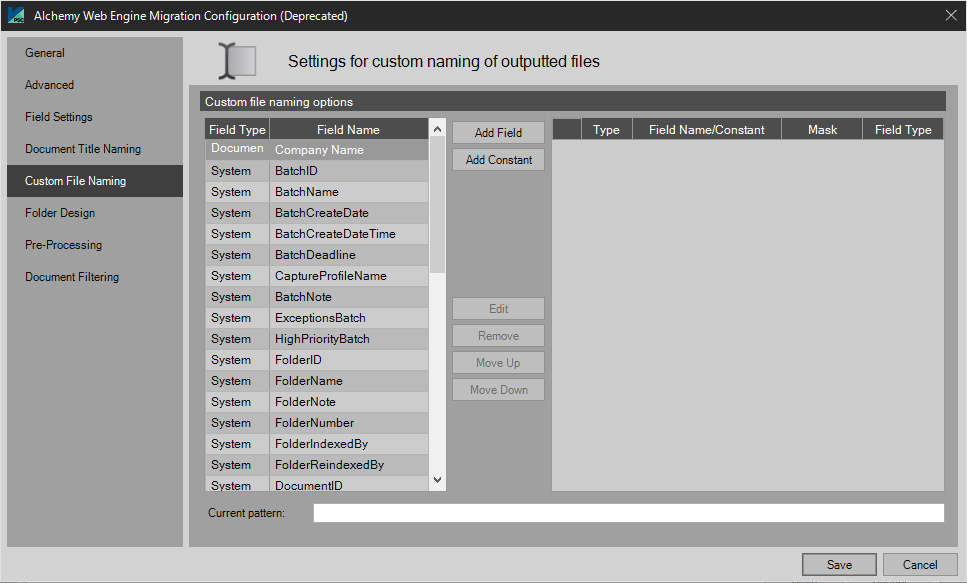
File naming tabs have a universal interface. The example shown here is the Custom File Naming tab. It supports the use of system and index data to name the files that are being migrated to the Alchemy Portal. For example, the Client, Platform, Batch_Number, and Load_Date as index fields could be concatenated to create a naming pattern for the migrated files in Alchemy.
These settings apply to custom files migrated.
File Extension is available with the Text migration settings. Users can add a custom file name.
Folder Design
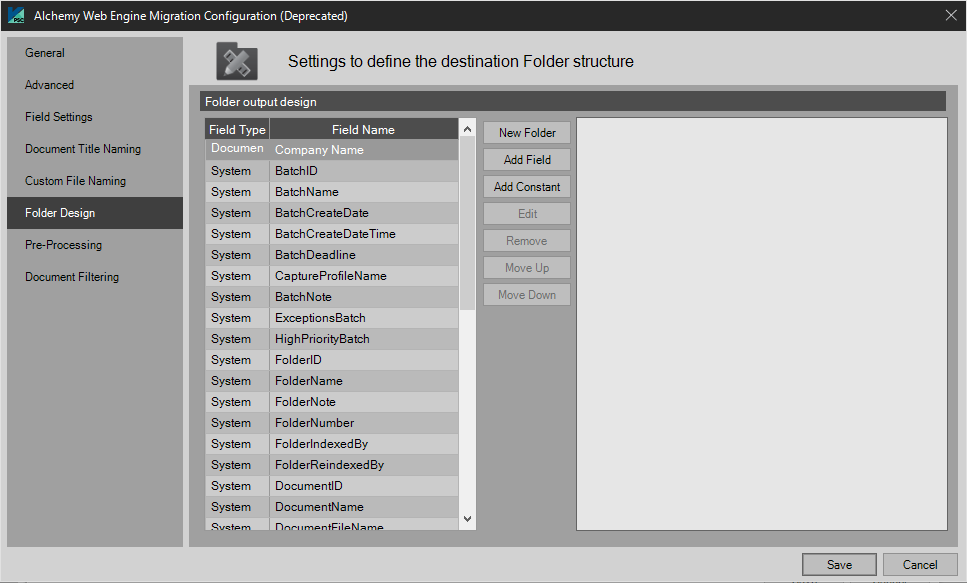
The Folder Design tab supports the use of system and index data in naming of the folders that are being migrated to the target system.
Folder Design should be constructed initially by the Alchemy Administrator, and then that same design can be customized here to match your Alchemy organization scheme.
Pre-Processing
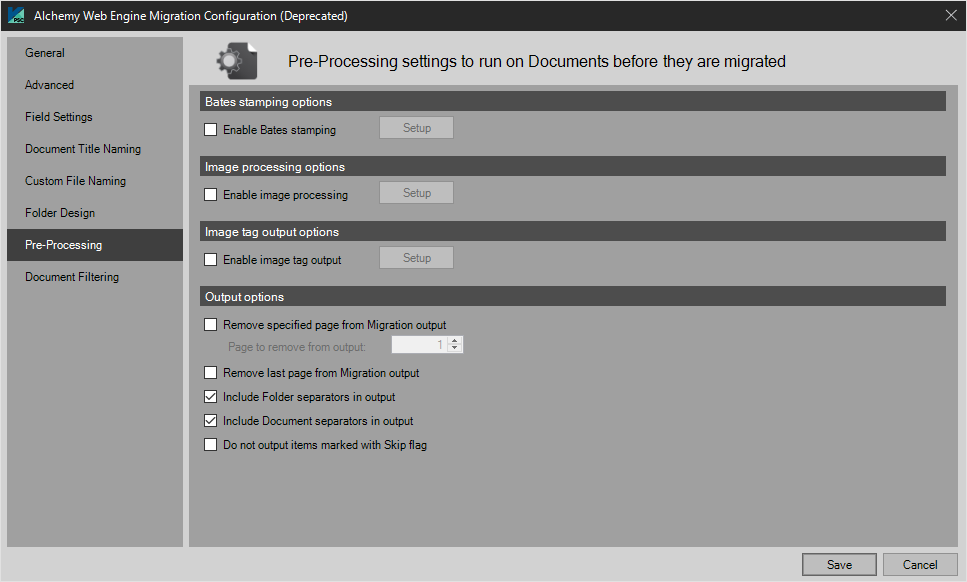
Bates Stamping Options
Bates Stamping is a legal industry standard for organizing and numbering multi-page legal documents. PSIcapture provides two methodologies for applying Bates Stamping: Capture Bates Stamping and Migration Bates Stamping. Capture based stamping applies Bates Stamps during the initial capture phase of a workflow. Migration based stamping applies Bates Stamps in the Migration phase of a workflow, which is typically the final phase.
See PSIcapture Administrator Guide: Bates Stamping
Imaging Processing Options
Select Enable Image Processing and then specify the image processing functions to run.
NOTE: The Enable Image Processing affects ONLY images files and not OCR. This feature is intended to be used when the desired images being migrated need a particular function run on them like Despeckle when the user has scanned in color and wishes a second output stream of Black and White images.
See PSIcapture Administrator Guide: Image Processing
Image Tag Output
See PSIcapture Administrator Guide: Image Tag Output
Output Options
Remove specified page from Migration Output: Page to remove from Output
A specified page from each document will be omitted from the output. NOTE: The Remove Page from Output affects ONLY images files and not OCR. This feature is intended to be used when the desired page to be removed is NOT a Folder or Document Separator. OCR is handled in the OCR Workflow Configuration section of this manual.
Remove last page from Migration Output
The last page from each document will be omitted from the output.
Include Folder Separators in Output
If data is included on the Folder Separator which is important to the user during Quality Assurance or Index but is NOT desired to be left in the output viewed by the end user; de-selecting this option will remove the Folder Separator sheet before outputting the file.
Include Document Separators in Output
If data is included on the Document Separator which is important to the user during Quality Assurance or Index but is NOT desired to be left in the output viewed by the end user; de-selecting this option will remove the Document Separator sheet before outputting the file.
Do not output items marked with Skip flag
Items marked with the Skip flag will be omitted from the output.
NOTE: The Keep/Remove Separators defined in migrations affects ONLY images files and not OCR. OCR is handled in the OCR Workflow Configuration section of this manual.
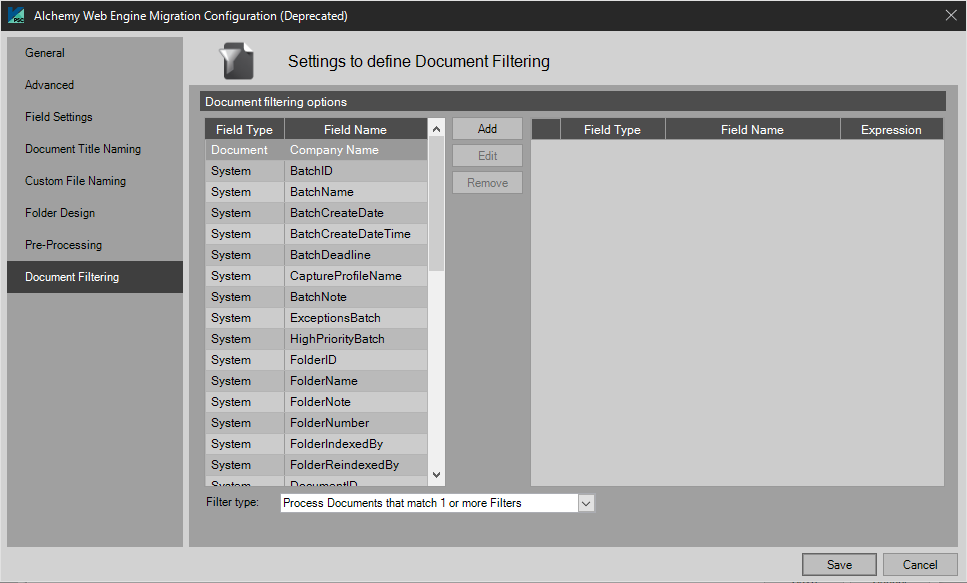
Document Filtering
Comments
Please sign in to leave a comment.